
Biomedicine may be a swamp of Chinese papermill fraud, but surely such respectable research disciplines like AI, big data, machine learning, internet-of-things, blockchain and neural networks are reliable, these peer reviewed papers in Springer, Elsevier and other trustworthy publishers must surely be beyond reproach?
Sure. Smut Clyde reports that many of these are not just utterly fake products by papermills, but even their reference sections are yet another business branch for crooks to buy and sell, where a customer in one field pays to be cited by mill papers in a totally unrelated field altogether. And because the traditional journal peer review consists of speed-checking if a manuscript complies to certain patterns and standards, nobody reads anything anymore before approving. Not even the titles, never mind references.
I personally am worried that the global academic fraudsters and papermillers have by now trained the scholarly publishing system to reject everything which looks like actual real science. Maybe this is why your last submission was recommended for “a more specialized journal”, dear reader?
Now, over to Smut Clyde. If you keep on reading, there will be some pistachios at the end.
Invisible Imperial Tailoring reaches new heights of sartorial creativity
By Smut Clyde

“Smart cities portray a very good vision for development for human beings. Traditional video surveillance only provides simple functions such as video capture, storage, and playback, which are difficult to use as an early warning and alarm. To ensure that abnormal behaviors are monitored in real time and effective measures are taken in a timely manner,…“
“Smart city framework based on intelligent sensor network and visual surveillance” displays a curious pattern of References. At some point the original text had become unmoored from its original References section, subsequently acquiring a replacement from some other source entirely, so that any resemblance to the in-text citations is purely coincidental. There is also the minor issue of Figure 1, stolen from “Pachube”, which back in 2008 / 2009 was the new multimedia-sharing platform that was going to displace YouToob.


Illustrations with unacknowledged pasts also occurred in “Design of multimedia blockchain privacy protection system based on distributed trusted communication” (Li et al 2021):
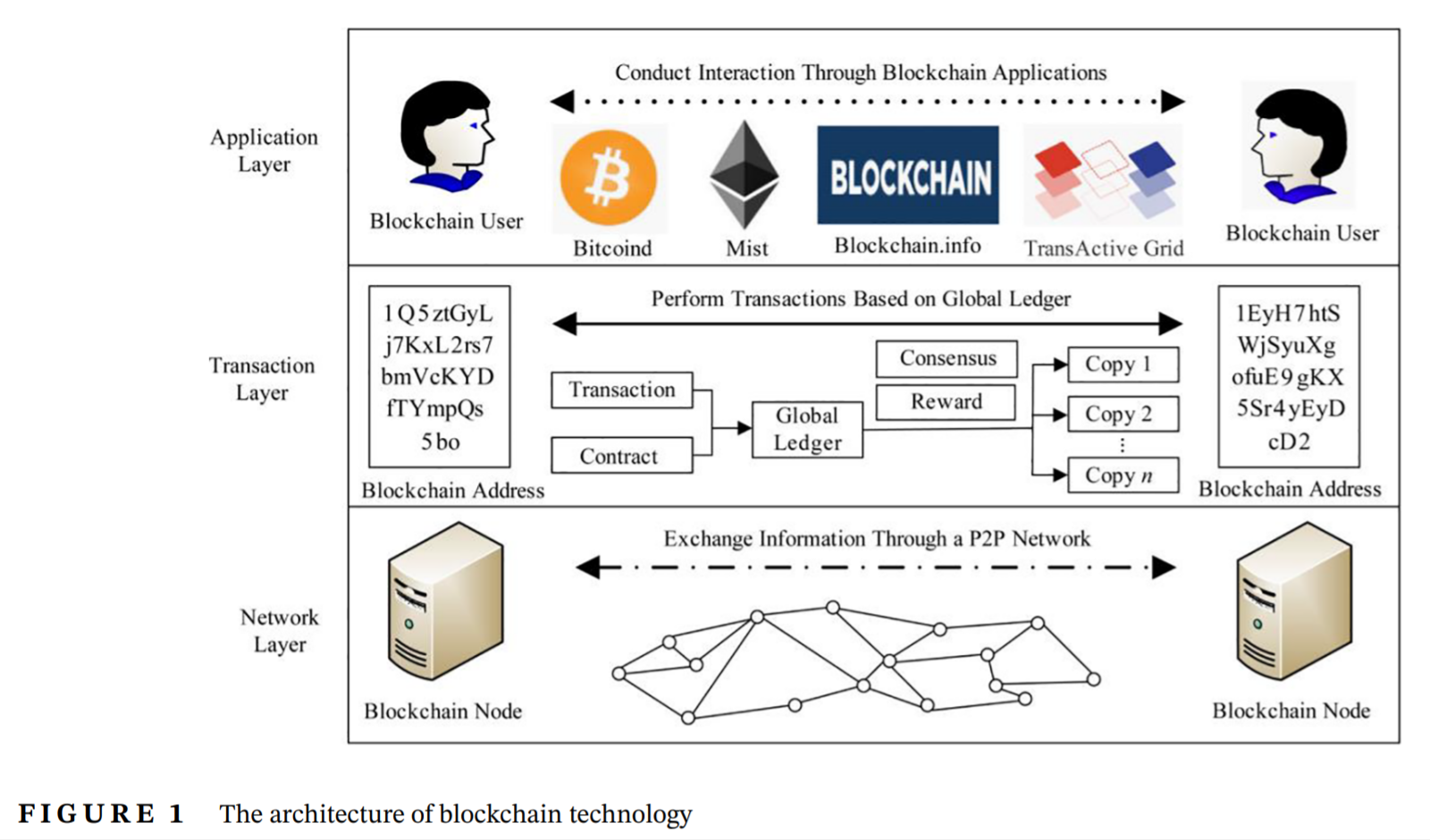
Curiouser still, similar citations / References mismatches occur a lot. They are frequent within, but not limited to, the opera of Li et al. Nor are they limited to just one journal. Within Neural Computing and Applications, in a Special Issue devoted to “intelligent computing methodologies in machine learning for IoT applications“,
“The submitted manuscripts were reviewed by experts from both academia and industry. After two rounds of reviewing, the highest quality manuscripts were accepted for this special issue”.
None of those academic and industry experts noticed that a single list of References had provided “Design of traffic object recognition system based on machine learning” (Li, Deng & Cai 2020) with a foundation, and – after slight rearranging – another platform for “Intelligent traffic monitoring and traffic diagnosis analysis based on neural network algorithm” (Wang et al 2020). Guest Editors Jinghua Zhao and Junyu Xuan did not notice either.


It is as if these paper-shaped artefacts were created by splicing together portions of two or three unrelated college messages, in the manner of an Exquisite Corpse. Could it be that essay mills provide free samples of their work, but omit the References lists as a way of discouraging freeloaders?
Illustrations, of course, can be stolen from anywhere. But the separate origins of those randomised replacement lists remain a mystery. Really Ionescu deserves to be added somewhere to the citations, for these bizarre juxtapositions feel like dialog from an Absurdist drama.
Alternative title: And the Hippos were Boiled in their Tanks
 “Further research and improvement of the object-oriented data model is needed to meet the needs of multimedia data management [28–31].”*
“Further research and improvement of the object-oriented data model is needed to meet the needs of multimedia data management [28–31].”*
[29]. Huang C, Lin W, Lai C, Li X, Jin Y, Yong Q (2019) Coupling the post-extraction process to remove residual lignin and alter the recalcitrant structures for improving the enzymatic digestibility of acid-pretreated bamboo residues. Bioresour Technol 285:121355
“Railway logistics organization based on information technology of railway logistics, based on the existing railway transportation optimization and integration of resources and cost, realize the rapid response of the logistics demand, to the development of railway logistics market and gain profit [6].“
[6]. Chomba C (2013) Factors affecting the Luangwa (Zambia) hippo population dynamics within its carrying capacity band Insights for better management. International Journal of Biodiversity and Conservation 5(3):109–121
Why bamboo lignin? Why hippos? From these two papers respectively:
- Li, Deng & Su “Multimedia Imaging Model of Information System Based on Self-Organizing Capsule Neural Network and Game Theory” Neural Processing Letters (2021) doi: 10.1007/s11063-020-10258-z
- Li & Zhang “Hierarchical evaluation algorithm of logistics carrying capacity based on transfer learning in multimedia environment” (Li & Zhang 2019) Multimedia Tools and Applications (2019) doi: 10.1007/s11042-018-6000-y
We began with Li, Deng and Cai, but they are only an entry-point to an entire pseudo-scholastic literature, loosely characterised by its Worship Words… such as Big Data; Internet of Things; Machine Learning; Multimedia; Fuzzy Intuitive Logic; deep learning, Convolutional Neural Networks, Backward Propagation, unsupervised training; tracking; figure recognition. It is an
Einstein Buzzword Intersection. A Cloaca Maxima of pseudo-scholastic journals sprang up to cater to this literature, all based on the principle that a manuscript containing two or more of these Worship Words is displaying deep gnomic wisdom, rather than being total bullshit.
As is the custom of my people, I prepared a spreadsheet.
We earlier glimpsed the work of this Bafflegab Industry in the context of Multimedia Tools and Applications or MTAP (a Springer journal) and Journal of Visual Communication and Image Representation (from Elsevier). There is also an overlap with the Fuzzy-Logical charivari of charlatans encountered more recently.
For people who enjoy contributing to PubPeer, Special Issues of these journals are reliable orchards of low-hanging fruit, or barrels of easy-target fish if you prefer.
- Big data analysis techniques for intelligent systems (Journal of Intelligent & Fuzzy Systems, 2019) – edited by Ahmed Farouk, Dou Zhen
- Intelligent data aggregation inspired paradigm and approaches in IoT applications (Journal of Intelligent & Fuzzy Systems, 2019) – edited by Xiaohui Yuan, Mohamed Elhoseny
- Computational Human Performance Modelling for Human-in-the-Loop Machine Systems (Journal of Intelligent & Fuzzy Systems, 2020) – edited by Hoshang Kolivand, Valentina E. Balas, Anand Paul and Varatharajan Ramachandran.
- Special Issue: Recent Advances in Pattern Recognition and Machine Vision (PRMV2018) / Special Issue on Parallel and Distributed Computing and Networking (CANDAR2018) (Concurrency and Computation: Practice and Experience, 2021).
- Special issue on Machine Learning for Emerging Cognitive Internet of Things (Cognitive Systems Research, 2018) – Edited by Gustavo Ramirez Gonzalez, Enas Abdulhay.
Or if you obtain your minimum daily recommended intake of Schadenfreude by reading Retraction Watch, then read on!
Elsevier are Deeply Concerned about 400 paper-shaped hairballs that found their way into Microprocessors & Microsystems. Meanwhile, Journal of Intelligent & Fuzzy Systems comes from IoS Press. Incursions of nescience required the retraction of multiple Special Issues of that publisher’s journals, evidently seen as a soft target: “these articles cite literature sources that have no relation to the subject matter of the citing article”.
Li, Deng and Cai purported to be authors of one of the papers swept up in the JIFS tranche of retraction. Yes, there were plagiarised images.
- Li et al “Design of intelligent community security system based on visual tracking and large data natural language processing technology” Journal of Intelligent & Fuzzy Systems (2020) doi: 10.3233/jifs-179789


Not publishing Special Issues is not an option

But the most extreme Surrealist juxtapositions – a post-modern crescendo of interdisciplinary mashups – were hosted in a series of Special Issues in the Arabian Journal of Geophysics, and one from Personal & Ubiquitous Computing, from Springer. Imagine my disappointment, that no-one has written “A Back-Propagating Sloth Algorithm to Optimise the Encounters of Sewing Machines and Umbrellas on an Operating Table”.
- Fan, Research on coastal atmospheric change and Latin dance performance based on target detection network Arabian Journal of Geosciences (2021) doi: 10.1007/s12517-021-08214-9
- Zhang, Structure of plain granular rock mass based on motion sensor and movement evaluation of dancers Arabian Journal of Geosciences (2021) doi: 10.1007/s12517-021-07936-0
- Geng, The change of groundwater quality in shallow layer based on parameter estimation and tennis physical fitness recovery Arabian Journal of Geosciences (2021) doi: 10.1007/s12517-021-08009-y
- Liu et al, Detection of PM2.5 in mountain air based on fuzzy multi-attribute and construction of folk sports activities, Arabian Journal of Geosciences (2021) doi: 10.1007/s12517-021-08210-z
The retraction notice for the latter went, highlight mine:
The Editor-in-Chief and the Publisher have retracted this article because the content of this article is nonsensical. The peer review process was not carried out in accordance with the Publisher’s peer review policy. Guanming Liu has not responded to correspondence regarding this retraction. The Publisher has not been able to obtain a current email address for authors Lin Gan, Huailong Yang and Changyue Wang.
The scale of the Arabian Journal of Geophysics debacle overshadowed the situation at Personal & Ubiquitous Computing, where only a single Special Issue had been affected (“Autonomous vehicles: model development, policy design and system optimization“) with only 24 papers.
 In an overlapping literature of pseudo-scholarship, old-school Genetic Algorithms for problem-solving have mutated and evolved (by way of Particle-Swarm Optimisation) into a bestiary of biologically-inspired optimisation algorithms: ant colonies, wolf-packs, chickens, bats, salps, bee-hives, fireflies… one is never quite sure whether a given paper is proposing a new approach to the general problem of finding the global maximum of a multidimensional landscape with many local maxima (formed by a complex function with many parameters within a high-dimensional space), or is just describing animal behaviour. I am disappointed again by the absence of “A Treatise on the Steppenwolf Algorithm”. Again, many many journals are affected, with more Special Issues than you could shake a Stick Algorithm at.
In an overlapping literature of pseudo-scholarship, old-school Genetic Algorithms for problem-solving have mutated and evolved (by way of Particle-Swarm Optimisation) into a bestiary of biologically-inspired optimisation algorithms: ant colonies, wolf-packs, chickens, bats, salps, bee-hives, fireflies… one is never quite sure whether a given paper is proposing a new approach to the general problem of finding the global maximum of a multidimensional landscape with many local maxima (formed by a complex function with many parameters within a high-dimensional space), or is just describing animal behaviour. I am disappointed again by the absence of “A Treatise on the Steppenwolf Algorithm”. Again, many many journals are affected, with more Special Issues than you could shake a Stick Algorithm at.
All credit goes to the stalwart efforts of one anonymous PubPeer contributor (Rhipidura albiventris) and four onymous researchers (Guillaume Cabanac, Alexander Magazinov, Cyril Labbé, N. H. Wise) who have been exploring this phenomenon for a while.
Disguising stolen text with manual applications of Roget’s-Thesaurus synonym lists is not new, but now has been automated. Cabanac, Labbé and Magazinov noticed and wrote about ‘tortured phrases’ as a common method of generating Lorem-Ipsum papers to fill a journal’s pages, see their preprint:
Guillaume Cabanac, Cyril Labbé, Alexander Magazinov Tortured phrases: A dubious writing style emerging in science. Evidence of critical issues affecting established journals (2021) arXiv:2107.06751
Basically this is plagiarism, disguised by using software to replace key words and phrases with paraphrased approximate synonyms. The pillaged material becomes less recognisable — though also stilted and incomprehensible (as if Google-translated through a chain of different languages), without any impact on publishability. Fortunately the substituted terms are dumbprints whereby phrase-tortured texts can be automagically identified.
Algorithmically-generated papers are common in the spigots included here (JIFS, Arabian Journal of Geophysics), as a source of material to be finished with meaningless lists of References. In fact plain, unadorned plagiarism still occurs, with little attempt at disguise, for we are not dealing with master criminals here. And I mustn’t forget programs that assemble text without any pretense to meaning (successors to SciGEN as it were): GPT-2 shows up as well. But whatever strategy was used to put a lot of words together for a publication, attention to the citations is another way of identifying them.
Clearly these intersections of computer-science-adjacent bafflegab suffer from a Sokal Test problem. If editors and reviewers can’t tell substantive papers (reporting genuinely new algorithms or data structures or applications) from vaporous word-wooze, does the field deserve any academic recognition or funding? Though there is the consolation of no-one reads all this technobabble, least of all the journal editors and reviewers, so it does little active damage other than the diversion of funds.
It is tempting to blame Open Access for all this, but most of the journals follow the ‘subscription’ model… institutions are being charged for access (which none of them want). From one perspective, the problem is that the Buzzword Intersection is home to too many journals, with all the large academic publishers starting a few (or acquiring them) to avoid missing out on the goldrush; also to pad out the bundles of journals that they offer to libraries, in order that those subscription bundles will look less like a bad deal. This leaves them with the problem of filling pages in these ‘long tail’ journals, but fortunately there are people available to help, as long as obstacles like ‘standards’ aren’t put in their way.
Anyway, the generated content often appears in the regular issues of journals, rubber-stamped by the regular editors and peer-reviewers in preference to admitting their failure to understand. Even so, journals and publishers are happy for attention to focus on the case of Special Issues (when the incoherent jibber-jabber appeared under the aegis of some Guest Editor who proposed a topic and volunteered to recruit contributors). Especially when the ‘guest editors’ were papermill noms-du-plume using fake email addresses, or a coterie of sock-puppet peer-reviewers, to fast-track mass-produced word-salad into a journal’s pages. So the journals promise to close the loophole “configuration error” and make their systems less hackable, and then everyone is distracted by a squirrel. The idea of not publishing Special Issues is not an option, because of business models.
In this regard, a blog post by Igor Pak from late 2020:
“And if you are one of those scam journal publishers who keep emailing me every week to become a special issue editor because you are so enthralled with my latest arXiv preprint — you go die in a ditch!”
Visionary words of Mohamed Elhoseny
But often these piratical guest-editors do have valid authenticated e-addresses and identities. Far from being pseudonymous papermill-stovepipes, they’re recognised con-men and chancers. So here’s Mohamed Elhoseny (a.k.a. M. R. Ibraham). According to his mentor Xiaohui Yuan:
“It was 2014 when Dr. Mohamed Elhoseny joined the Computer Vision and Intelligent Systems lab at the University of North Texas, Denton, Texas, USA, where I have served as the director since 2006. Our research interests align in the field of artificial intelligence, in particular, optimization methods for wireless sensor network. Dr. Elhoseny is a rising star researcher in the field of wireless sensor network and, to my best knowledge, Dr. Aboul Ella Hassanien is an established researcher in this field. This book is a pioneering effort on the dynamic wireless sensor networks, which focuses on the smart applications. In-depth discussions on the security measurements, large volume of data, and intelligent analysis shed new lights on the future research and development of sensor networks in the era of Internet-of-things and big data. The readers will find extraordinary values in its visionary words.”
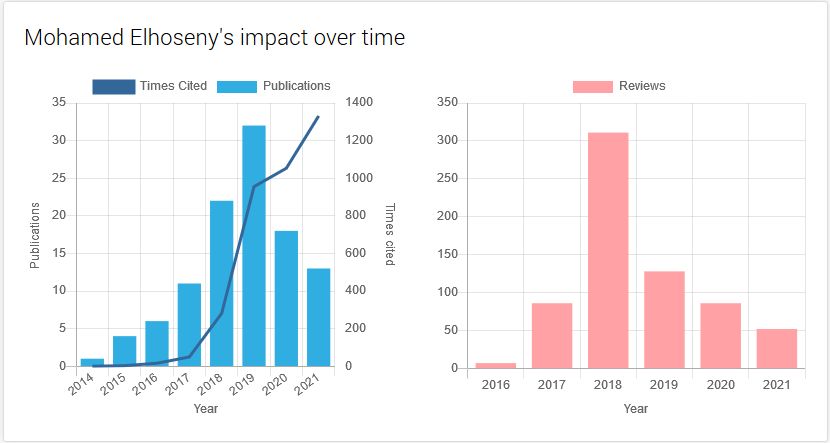 The source there is Yuan’s Foreword to “Dynamic Wireless Sensor Networks: New Directions for Smart Technologies“ (Elhoseny & Hassanien 2018) (Vol 165 of Studies in Systems, Decision and Control), an actual book for which Springer would like you or your library to pay €120.
The source there is Yuan’s Foreword to “Dynamic Wireless Sensor Networks: New Directions for Smart Technologies“ (Elhoseny & Hassanien 2018) (Vol 165 of Studies in Systems, Decision and Control), an actual book for which Springer would like you or your library to pay €120.
The separate Reference sections after each of its eight chapters provide a detailed, cross-indexed guide to the thoughts and derivative papers of M. Elhoseny. Given his productivity and self-promoting, credit-grabbing shamelessness, naturally Elhoseny is sought-after by publishers to edit books and journals (as are others of his clique). Even if their editorial contributions are limited to extending each list of spurious, meaningless citations by inserting more irrelevant references en bloc… ones that tout their own CVs. A reputation in the field, and the enviable status of Highly-Cited Researcher, are built on the arts of citation farming and extortion.
Elhoseny / Ibrahim recently expunged his autohagiographic website in response to the unexpected attention he was receiving from PubPeer, but if anyone is interested in his full CV, a copy was archived on the Wayback Machine.
Re #5: this link has been archived on January 17, 2021, see https://web.archive.org/web/20210117102916/https://www.mohamedelhoseny.com/international-journal-editorial-services
The latest archive of the website was recorded on September 3, 2021: https://web.archive.org/web/20210903143634/http://www.mohamedelhoseny.com/

All things considered, it was probably an error for IoS to invite Elhoseny and his old mentor Xiaohui Yuan to guest-edit a special issue of Journal of Intelligent & Fuzzy Systems with “Intelligent data aggregation inspired paradigm and approaches in IoT applications” as the topic. The 50 papers contain an inordinate number of Elhoseny citations: he was most- or second-most-cited author in 21 of them [H/t Schizomeris leibleinii]. Other beneficiaries of the citational largesse included S. K. Lakshmanaprabu, Weiping Zhang and Xiaohui Yuan. For every paper that was accepted, peer-reviewers supposedly had to read and reject another five that were even worse.
“We through the call for paper through some conference and research community, we collected more than 300 papers. Based on the peer-review comments, we carefully selected 50 papers for this special issue.“
Introductory Editorial

Another JIFS Special Issue, on “Big data analysis techniques for intelligent systems“, was edited by Ahmed Farouk and Dou Zhen — which is to say by sockpuppets or meatpuppets rather than directly by Elhoseny. Here the 50 accepted papers acquired an average of 3.72 Elhoseny citations each.
“We through call for paper through some conference and research community, we collected more than 246 papers. Based on the peer-review comments, we carefully selected 50 papers for this special issue.“
In many of the examples these citations were injected after the manuscript had been finished and submitted, so they interrupt the nice order of in-text citation numbers; producing sequences like 1 .. 2 .. 3 .. 4 .. 23 .. 24 .. 25 .. 26 .. 5 .. 6 (that is, the papers are appended at the end of the References section, even if they were cited early in the Introduction). Whether the putative authors knew of and agreed to the Elhoseny fan-service is unknown. As well as this editorial molestation, we even find Elhoseny inserted as a post-facto co-author of these fabrications. He must be so proud.
In an earlier blogpost we encountered citation extortion from Luming Zhang during his tenures at MTAP and JVCIR. A colleague proposed Ye Liu (Zhang’s occasional co-author) as another rising star of multimedia blather, whose citation-driven ascent of academic status followed a pattern suggestive of shenanigans. We’ll come back to him.
N. Arunkumar, a polymathic charlatan
All that is in the way of a digression, because two forms of citational malpractice are at play here, slightly different (though overlapping). Editorial malfeasance is distinct from my main theme: this novel form of papermilling where college-level essays have their missing References sections replaced. Depending on the anticipated level of scrutiny, we might find bespoke References with a vague congruence to the text, obtained by G**gle consultation, but sometimes the replacement is a default, off-the-rack template, with completely nonsensical citations.
Which leads to the other aspect of bogus References section. They have beneficiaries, for citations are the currency of the academic marketplace. It may even be that ambitious researchers are paying the papermillers to include their works in these templates.
Now I am not saying that everyone who benefits from inclusion in these recycled strips of Reference Wallpaper has engaged in a quid-pro-quo. But some names do feature more than chance would explain… for instance, N. Arunkumar and his colleagues. When Arunkumar’s regular collaborators Gustavo Ramirez Gonzalez and Enas Abdulhay guest-edit a Special Issue (“Machine Learning for Emerging Cognitive Internet of Things”), and their names along with his dominate a strip of Reference Wallpaper that turns up with minor variations in multiple papers, it is irresponsible not to speculate.

Arunkumar is a polymathic charlatan, with papers on diagnosing diabetes with “Ayurvedic pulse”, and EEGs for the taxonomy of epilepsy, and a Cuttlefish Algorithm for diagnosing Parkinson’s Disease, and “Brain-actuated wireless mobile robot control through an adaptive human-machine interface”, and nasopharyngeal carcinoma, and so much else. All highly cited, and all basing their prominence on Reference-section wallpaper tacked onto bogus papers in corrupted journals.
The rogue editors, the papermillers and the citation beneficiaries form a troika, but the roles probably blur. The highly-promoted authors may even be actively involved in the papermilling.
The useful aspect of all this (for certain values of “useful”) is that a paper that’s more widely cited than its novelty explains (or even better, a co-occurrence of papers) can be a tool for finding more crappy little Reference-wallpapered publications. It is a game that anyone can play, and readers are invited to join in.

Fish in Goofle Scholar for any item from the Arunkumar Wallpaper list — say, “Intelligent Bézier curve-based path planning model using Chaotic Particle Swarm Optimization algorithm” — and browse down through the papers that cite it. After the self-citations at the beginning, the list is a scornucopia of abjection. As well as that Special Issue in Cognitive Systems Research, we find other garbage papers spilling out into regular issues without the excuse of Rogue Editors to explain their acceptance. Many found welcoming homes in Journal of Supercomputing. One example will have to suffice:
- Zhang & Li, “Multi-label algorithm based on rough set of fractal dimension attribute” The Journal of Supercomputing (2020) doi: 10.1007/s11227-018-2522-3
Clusters of Arunkumar citations find strange bed-fellows. The same Reference Wallpaper often drags in in a few random papers with a macromolecular theme.
- “Amphiphilic Macromolecule Self-Assembled Monolayers Suppress Smooth Muscle Cell Proliferation”
- “Micellar and structural stability of nanoscale amphiphilic polymers: Implications for anti-atherosclerotic bioactivity”
- “Synthesis and characterization of PEGylated Bolaamphiphiles with enhanced retention in liposomes”
- “Tartaric Acid-based Amphiphilic Macromolecules with Ether Linkages Exhibit Enhanced Repression of Oxidized Low Density Lipoprotein Uptake”
- “Textile Frequency Selective Surface”
- “Probing Nanostrain via a Mechanically Designed Optical Fiber Interferometer”
- “A Fe-C coated long period fiber grating sensor for corrosion induced mass loss measurement”
These may well be blameless, chosen by the papermillers at random to pad out their material. I include them here only as additional threads into the junk-paper labyrinth. They lead to more papers in that “Machine Learning for Emerging Cognitive Internet of Things” Special Issue, but also to mass-produced page-fillers in International Journal of Computers and Applications.

The Bovine Indigestion Quartet
A tetrad of innocuous papers about intestinal and hepatic dysfunction in cattle (specifically in ketotic cattle, in two papers) often appear without Arunkumar. The presence of the Bovine Indigestion Quartet (by coincidence, this is also the name of my jazz-punk Klezmer band) is an indication that a publication is Bullshit. The papermillers may even intend it that way.
Two, three or all four members of the quartet are the unifying feature of a mini-genre of coordination-chemistry papers, supporting claims about cancer epidemiology (!) or about the biological properties of a class of chemicals (!!).


- Song, Li & An “Two New Dy(III) and Cu(II) Coordination Polymers: Crystal Structures and Anti-liver Cancer Activity” Journal of Inorganic and Organometallic Polymers and Materials (2018) doi: 10.1007/s10904-018-0850-7
- Song, Li & An “Crystal Structure and Biological Evaluation of Two Novel Organic-Inorganic Hybrid Materials as Antitumor Agents in the Treatment of Liver Cancer” Journal of Chemistry (2018) doi: 10.1155/2018/9758197
- Fan, Shen & Zhou “Novel Pyran and Polyhydroquinoline Derivatives: Inhibiting Human Osteosarcoma Activity” Russian Journal of General Chemistry (2018) doi: 10.1134/s1070363218060336
- Dong et al “Crystal Structure and Anti-Ovarian Activity of Two Novel Coordination Polymers [Cu2(o-Сpia)(OH)(Bitb)0.5]n and {[Zn7(OH)4(Bta)4(H2O)2](H2NMe2)2(DMF)3}n” Russian Journal of Coordination Chemistry (2018) doi: 10.1134/s1070328418090026
- Sheng et al, “Two novel Mn (II) and Zn (II) complexes: crystal structures and anti-prostatic cancer activity” Main Group Chemistry (2018) doi: 10.3233/mgc-180264
- Han et al, “Novel coumarin derivatives: Synthesis, anti-breast cancer activity and docking study” Main Group Chemistry (2019) doi: 10.3233/mgc-180682
Thank you for pointing out our mistakes. We have carefully checked our references. Due to the limited ability of English writing, the author did imitate the way that other related articles were written.These mistakes do not affect the experiment, scientific findings and conclusions made in this article, but we must sincerely apologize for this. We could upload raw images to the website. We will check more carefully and thoroughly each reference when writing articles in the future. Thanks for your constructive comments again.
The Bovine Indigestion Quartet also distinguished certain paper-shaped accretions of bafflegab in NeuroQuantology from the run-of-the-mill jibber-jabber comprising the rest of the issues. You might deduce from the journal title that it invites the submission of hairballs of mind-numbing nescience, but I couldn’t possibly comment.
- Liu & Wang, “Water Disaster Risk Perception and Behavior Strategy Analysis Based on the Neurology of Consciousness” NeuroQuantology (2018) doi: 10.14704/nq.2018.16.5.1270
- Feng Ren, “Imaging Experiment of Brain Cognitive Activity Based on EEG and Its Philosophical Influence” NeuroQuantology (2018) doi: 10.14704/nq.2018.16.5.1271
- Su & Yang, “Analysis of the Characteristics of Thinking Control during Basketball Free Throw Based on Electroencephalogram” NeuroQuantology (2018) doi: 10.14704/nq.2018.16.5.1272

A more eclectic strip of References Wallpaper encompasses a broader literature, sampling papers about shadow removal, plant recognition, copy-move forgery, diseased leaves, mining projects, bamboo, concrete, lignin, and circular targets. The Hippo citations are less common. Fishing for random items from this starter-kit of weird bollocks brings up papers in a combined Special Issue of Concurrency and Computation: Practice and Experience, on “Recent Advances in Pattern Recognition and Machine Vision (PRMV2018)” and “Parallel and Distributed Computing and Networking (CANDAR2018)”. Elsewhere, papers in (so far) International Journal of Communication Systems, International Journal of Speech Technology, Neural Processing Letters and International Journal of Computers and Applications. To be fair, the journal titles are designed to give readers fair warning that these are fraud-friendly environments.
I tried this approach with Ye Liu’s CV. Again, a cluster of his papers and presentations are cited en bloc, especially within MTAP and Concurrency and Computation, despite their irrelevance to the context (one is free to speculate about the identities of those journals’ editors and reviewers). Inquiring minds are wondering how much “Fortune teller: Predicting your career path” and “From action to activity: sensor-based activity recognition” contributed to “Adaptive control for a hypersonic vehicle based on evolutionary algorithm and convex optimization” (Xu & Li 2021).

The overrated physical embodiment of Johnwb R. Lewis
Asked about the mass withdrawal of Special Issue papers, Ivan Oransky from Retraction Watch observed that “The papers are so obviously terrible, so why would you want them on your CV?” It is tempting to conclude that even the author identities are fake, so that no-one reaps a benefit from these opuscules and bagatelles except the recipients of the citations they contain… who are most likely the persons who concocted these confections and submitted them to garbage journals like JIFS.
Who actually benefits from this type of fraud? Is it the authors or is this a scheme to gain citations? The latter is much safer, since it is very hard to prove a connection. I’m thinking of paper mills that sell citations rather than authorships. You could only prove this, if you get access to the mills data. Does anyone keep track whether there are people out there who get a significant portion of their citations from such papers?
But the ‘false authorship’ proposal is refuted by those surveillance enthusiasts, Li Daming, Lianbing Deng and Zhiming Cai: they do list dozens of these algorithmic compositions on their CVs, in the absence of anything genuine to list.

Two of these papers signed by the Li/Deng/Cai group stand out for a high number of Ye Liu citations. Three others donate citations to a Zhenfeng Shao, balanced by others for D. Li. Self-citations are perhaps an optional extra that one can request from the papermillers… unless Li et al are the papermillers.
- Li et al, “A novel CNN based security guaranteed image watermarking generation scenario for smart city applications” Information Sciences (2019) doi: 10.1016/j.ins.2018.02.060
- Deng et al “Smart IoT information transmission and security optimization model based on chaotic neural computing” Neural Computing and Applications (2020) doi: 10.1007/s00521-019-04162-4
- Li, Deng & Cai, “Intelligent vehicle network system and smart city management based on genetic algorithms and image perception” Mechanical Systems and Signal Processing (2020) doi: 10.1016/j.ymssp.2020.106623
- Li, Deng & Cai, “Evaluation method of sponge city potential based on neural network and fuzzy mathematical evaluation” Journal of Intelligent & Fuzzy Systems (2020) doi: 10.3233/jifs-189031
- Deng, Li & Cai, “Emergency management system of urban waterlogging based on cloud computing platform and 3D visualization” Journal of Intelligent & Fuzzy Systems (2020) doi: 10.3233/jifs-189040
We do see some fake co-authors, of course: fictitious US collaborators, which in the minds of the papermillers makes the charade marginally more plausible. Throwaway student email accounts from community colleges are popular for this purpose, perhaps for the cachet of a “.edu” suffix.
- Shuicheng Tian, Kai Tang, Pengfei Yang, Aifang Jia & Hailey Melvin “Secure cloud computing model for communication network management” Journal of Intelligent & Fuzzy Systems (2019) doi: 10.3233/jifs-179060 (hmelvin@student.cccs.edu)
- Ling Zhao, Lijiao Chen, Qing Liu, Mingyao Zhang & Henry Copland “Artificial intelligence-based platform for online teaching management systems” Journal of Intelligent & Fuzzy Systems (2019) doi: 10.3233/jifs-179062 (henry.copland@pcc.edu))
- Hua Peng, Liang Liu, Jiayong Liu & Johnwb R. Lewis [sic!] “Network traffic anomaly detection algorithm using mahout classifier” Journal of Intelligent & Fuzzy Systems (2019) doi: 10.3233/jifs-179072 [jlewis55@my.polk.edu])
- Lizheng Liu, Fangai Liu & Byron Ky “Data mining-based model for motion target trajectory prediction” Journal of Intelligent & Fuzzy Systems (2019) doi: 10.3233/jifs-179093 [byron.ky@my.tccd.edu])
Li, Deng and Cai first came to the attention of Retraction Watch for identity theft: they appropriated a UK researcher’s name to adorn two of their papers as a fantasy co-author. I seriously doubt whether anyone read these confections even before retraction, but they have accrued 100 and 19 citations from other papers… many of those being equally upsilon-bindlestiff-boilermaker. On these two papers and many unretracted others, our friends share authorship with Harry (Haoxiang) Wang of Cornell University and GoPerception Laboratory, who may well be real, as he has multiple bogus publications without them. Anyway, physical embodiment is much over-rated.
- Deng et al Mobile network intrusion detection for IoT system based on transfer learning algorithm Cluster Computing (2019) doi: 10.1007/s10586-018-1847-2
- Cai et al, A FCM cluster: cloud networking model for intelligent transportation in the city of Macau Cluster Computing (2019) doi: 10.1007/s10586-017-1216-6
- Jiang & Wang, Application intelligent search and recommendation system based on speech recognition technology International Journal of Speech Technology (2021) doi: 10.1007/s10772-020-09703-0
- Fan, Zhou & Wang Urban Landscape Ecological Design and Stereo Vision Based on 3D Mesh Simplification Algorithm and Artificial Intelligence Neural Processing Letters (2021) doi: 10.1007/s11063-021-10442-9
We should also note the possibility of an elaborate Sokal hoax, embracing hundreds of papers from scores of imaginary authors, all intended to discredit this academic niche. If that’s the goal, it’s not working fast enough.
Harry Wang of Cornell
Another perspective on this whole imbroglio is provided by some of those widely-reused References I mentioned, about ‘removing shadows’ and ‘plant recognition’, that serve as markers for problematic papers (because they are cited in nonsensical contexts, illustrating or supporting irrelevant points). They seem to be blameless niche papers, swept up in Reference Wallpaper as mere circumstantial detail, until we look more closely and find Harry Haoxiang Wang as their author – often in senior position.
- (Qi Chen, Guping Zhang, Xingben Yang, Shuming Li, Yalan Li & Harry Haoxiang Wang “Single image shadow detection and removal based on feature fusion and multiple dictionary learning” Multimed Tools Appl (2018). doi: 10.1007/s11042-017-5299-0
- Shanwen Zhang, Harry Wang & Wenzhun Huang “Two-stage plant species recognition by local mean clustering and Weighted sparse representation classification” Cluster Comput (2017) doi: 10.1007/s10586-017-0859-7
- Shanwen Zhang, Haoxiang Wang, Wenzhun Huang & Zhuhong You “Plant diseased leaf segmentation and recognition by fusion of superpixel, K-means and PHOG” Optik (2018) doi: 10.1016/j.ijleo.2017.11.190
- And many more!
So this is the situation: H. H. Wang is someone who’s published a string of collections of buzzwords. He once went to Cornell University, and variously describes himself as “alumnus”, “Research Associate”, or “Associate Professor”. His academic affiliation is to his company GoPerception, which has no website and which does nothing. He is also a regular Guest Editor for Special Issues of journal-shaped garbage-scows like MTAP.

People pay to have contributions written for these Special Issues… of course they are all hand-waving incoherence and meaningless citations, in which anything is possible because Big Data and Unsupervised Learning and Internet of Things and Convolutional Neural Networks; but enough of those meaningless citations are to Wang’s buzzword compilations, so they’re accepted. Other people, perhaps, write their own artisanal hand-waving – then they’re provided with a list of suggested citations, with the advice that including these in the revised version of the manuscript will improve its prospects of being accepted.
Meanwhile other people commission contributions to regular issues of the same journals. These often include H. H. Wang citations as well (unless they rely instead on the magisterial work of Arunkumar, or Elhoseny, or others from this stratum of academia). Wang’s clients include the Li / Deng / Cai group where we started.
I don’t know whether there’s a single studio responsible for all this wordwooze, or several. The whole situation makes me tired and all I can hope for is that readers are now even tireder than me.
* * * * * * * * * * *
CODA (with pistachios!)
Part of a well-run papermill’s service is to handle the submission of papers and the correspondence with journals, using disposable email accounts so that the putative authors need not be involved, and there are many of these in the current corpus. But the email addresses in this corpus are often implausible, which is terrible trade-craft and offends my sense of professionalism. What the odds that all 11 “bullshit chemists” would independently choose to create email identities by modifying their names with ‘666’?
yan_jiang666@126.com, dongfengquan666@aliyun.com, huichun_chen666@yeah.net, xinhua_zhou666@yeah.net, jie_huang666@aliyun.com, qianqian_wang6668@aliyun.com, wei_gou666@yeah.net, da_li666@yeah.net, wei_zhong666@126.com, feng_li666@126.com, bin_zhang666@126.com
Worse, sometimes accounts are re-used. This creates email addresses that are even less plausible because they were inherited from some other customer.
I am also wondering why author Kou Xiaoming chose “xiemingd62@163.com” as the email address for correspondence. It was previously used by Xie Mingda, author of “A microwave absorbing material with soft magnetic nanoparticles based on negative refraction loss characteristics“.
Curiously, some of this account re-use crosses over into the trade in co-authorship. Either the papermillers diversified their operations, or some other operator acquired details of the email accounts.
Consider for instance the email identity ‘hhxiaoxiaohh21@163.com’, first attached to an Ellhoseny citation-delivery vehicle supposedly written by Xiao Han and published in Cognitive Systems Research. When it reappeared in 2021, it was attached to a study of genetic diversity in Alcea aucheri, contributed to Genetika (the organ of the Serbian Genetics Society) by a collaboration between five members of the School of mechanical and electrical engineering (North China institute of science & technology), and F. Faisal in Pakistan.
- Han, Gong & Zhan “Online labor service crowdsourcing analysis based on linear discriminant regression” Cognitive Systems Research (2018) doi: 10.1016/j.cogsys.2018.07.001
- Hang et al “Population genetic structure and gene flow in Alcea aucheri (Boiss.) Alef.: A potential medicinal plant” Genetika (2021) doi: 10.2298/gensr2102867h
A similar chain of events befell the email account ‘masxiongg@163.com’. This was first used (rather implausibly) by Li Dong Rui, who didn’t check references. Then again by Wang Hongmei from the Dept. of Physical Education, University of Science and Technology (Liaoning), in a collaboration that also included Majid Khayatnezhad from Iran, and F Faisal (again). They had studied genetic diversity in Salvia species to publish in Genetika, and I regret to say that they faked a gel, rather badly.
- Li, “Cluster analysis algorithm based on key data integration for cloud computing” International Journal of Reasoning-based Intelligent Systems (2017) doi: 10.1504/ijris.2017.090041
- Zhao et al, “Genetic diversity and relationships among salvia species by ISSR markers” Genetika (2021) doi: 10.2298/gensr2102559y
What we are seeing is probably a papermill that targets Genetika and caters to customers in South-West Asia, but they also sell co-authorship to Chinese academics (using that word in the broadest possible sense). Presumably the Chinese customers are recruited through a broker, who’s recycling email accounts previously used by the “References” papermill. Hence the collaborations. Yay Globalisation!
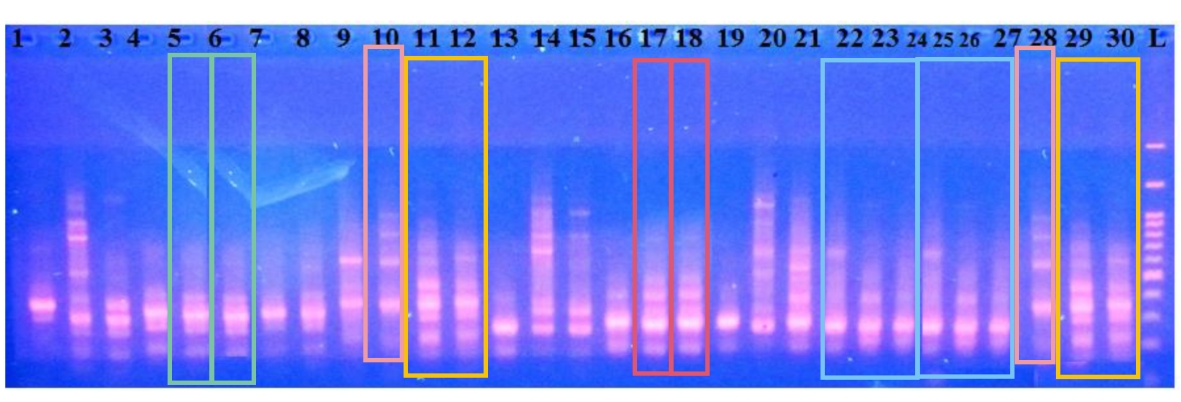
This is a departure from the subject of the post but I cannot ignore three more bad gels. Here is Fig 2 from Lejing Lin, Li Lin and Abdul Waheed. Don’t be like Fig 2.

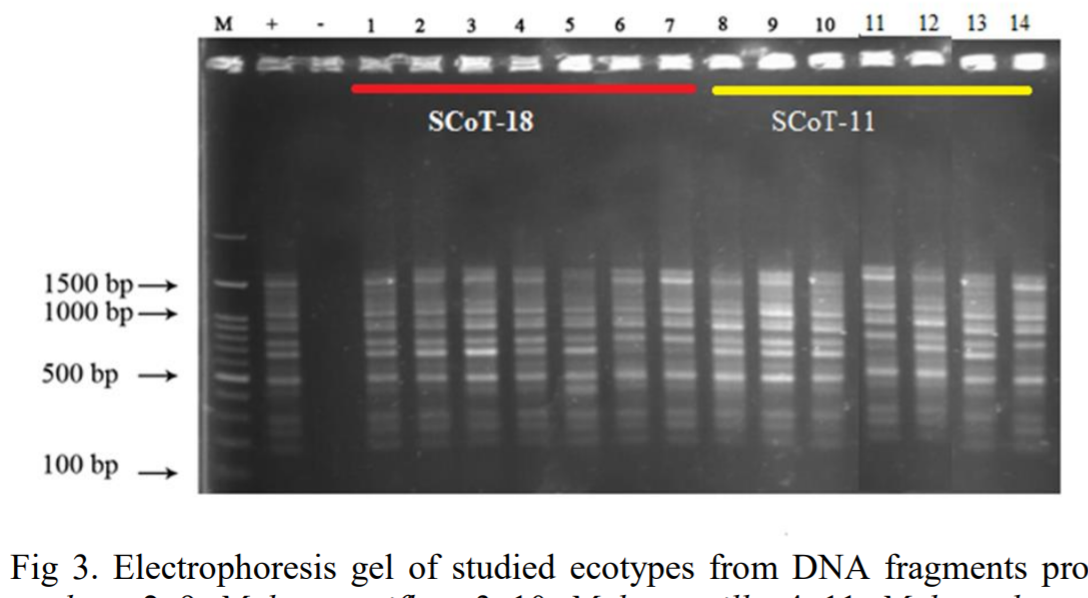
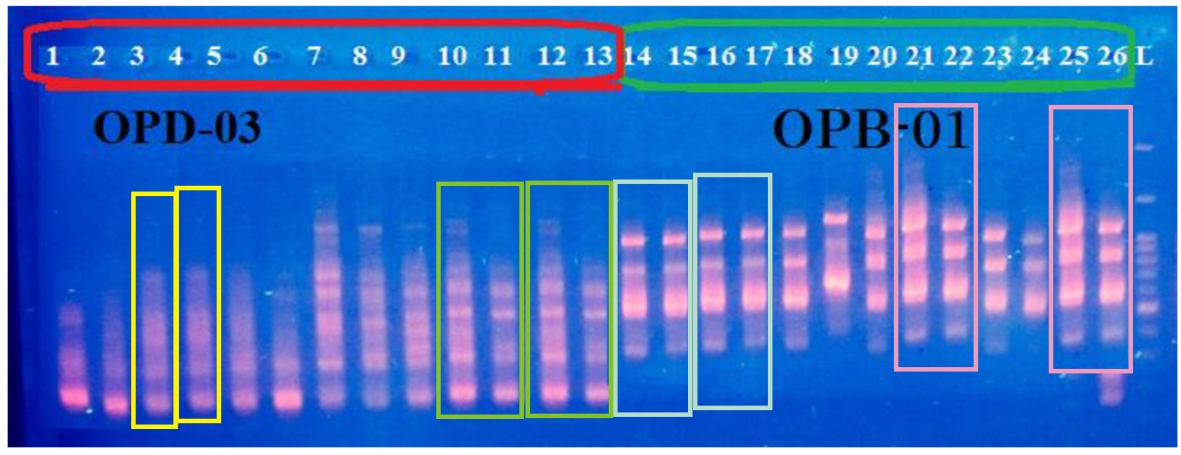
And here, Fig 3 from Li et al (2021); and Fig 4 from Yin, Khayatnezhad and Shakoor (2021). Curiously, Huixing Li and Juan Yin both chose to communicate with the editors of Genetika through the identity ‘ldongmei870@gmail.com’.
- Lin, Lin & Waheed “Assessment of genetic structure and diversity of Erodium (Geranaiceae) species” Genetika (2021) doi: 10.2298/gensr2102507l
- Li et al, “Study on genetic diversity between Malva l. (Malvaceae): A high value medicinal plant using SCoT molecular markers” Genetika (2021) doi: 10.2298/gensr2102895l
- Yin, Khayatnezhad and Shakoor “Evaluation of genetic diversity in geranium (Geraniaceae) using RAPD marker” Genetika (2021) doi: 10.2298/gensr2101363y
I have saved the best for last! For the diligence of the Genetika editors and reviewers gave us Wan, Zhang & Zhu, who can be reached at ‘carlorussohri@yahoo.com’. More to the point, their paper is mostly about Caveolin-2 expression as a marker of oral cancer; but then in the Discussion section, they switch to genetic diversity in pistachios. Another copy of the Discussion can be found (unchanged) in Mahdavi et al (2021) without Chinese co-authors. And a paragraph of the discussion appeared in the pistachio-centric work of Qian & Mehri (2021).

That last collaborating pair are also notable for using the email identity ‘xuanxuanww2@163.com’ — recycled from Wu & Zeng (2018), with its payload of Arunkumar citations.
- Wan, Zhang & Zhu “Expression of caveolin-2 in patients with oral cancer and correlations with clinicopathological parameters” Genetika (2021) doi: 10.2298/gensr2102703w
- Mahdavi et al “Genetic diversity and population structure of Iranian pistachio (Pistacia vera l.) cultivars” Genetika (2021) doi: 10.2298/gensr2102671m
- Qian & Mehri “Detecting DNA polymorphism and genetic diversity in a wide pistachio germplasm by RAPD markers” Genetika (2021) doi: 10.2298/gensr2102783q
- Wu & Zeng “Design of electro-hydraulic servo loading controlling system based on fuzzy intelligent water drop fusion algorithm” Computers & Electrical Engineering (2018) doi: 10.1016/j.compeleceng.2018.08.010
Alternative title #2:
Always…uh…never…forget to check your references


Donate to Smut Clyde!
If you liked Smut Clyde’s work, you can leave here a small tip of 10 NZD (USD 7). Or several of small tips, just increase the amount as you like (2x=NZD 20; 5x=NZD 50). Your donation will go straight to Smut Clyde’s beer fund.
NZ$10.00


Here is a question to consider re: using fake papers for the purpose of delivering citations, rather than benefiting the (supposed) authors. If a fake paper at some point gets discovered and retracted, that might affect the position of the author, or the paper-mill client as the case may be. But what happens to the citations? As far as I am aware, citations by retracted papers are still counted and contribute to the fame of the cited work. Also the quality of the journal from whence the citation occurs does not matter. Thus, a paper can become highly cited purely from garbage journals, and even from papers that eventually get retracted. The low quality of the citing literature is usually hidden behind a single number of citations.
LikeLike
This is timely: https://twitter.com/RetractionWatch/status/1467931948681211904
Links to “Metaphor-based metaheuristics, a call for action: the elephant in the room”
and to “Evolutionary Computation Bestiary”.
LikeLike
I have to confess that I spent more time in this cesspit, adding to the spreadsheet. Today’s finds include “Design of dual-frequency antenna for IoT applications” (Yang Yun-xing, Zhao Hui-chang , Chen Si , Zhang Shu-ning).
It looks like someone wrote an essay on designing antenna for proximity bombs. Our papermillers obtained a copy, and retrofitted it with citations and a References section (based on one of these Aronkumar-boosting wallpaper strips, which they extended by banging away at Google for 5 minutes) Then they added a title that was more Internet-of-Things-friendly, so they could send it off to the friendly editors at Cognitive Systems Research for a Special Issue on “Cognitive Wireless Networks Inspired Paradigm in IoT Applications”.
Of course the text is still all about proximity fuses…
“In this paper, an antenna designed for proximity fuse was presented … Fuse is a control system that detonates with target information and environmental information or under other predetermined conditions timely, while proximity fuse is used to detect physical field containing target information around target. Proximity fuse directly collides with the target to works without the projectile. Therefore, the antenna in proximity fuse system is different from other fuse antennas, and its radiation pattern shows oblique radiation [1], as shown in Figure 1.”
The theoreticians of the IoT imagined various household appliances talking to one another, but I’m not sure if they envisaged proximity bombs as part of that conversation.
LikeLike
Pingback: Grande successo di pubblico – ocasapiens
Now covered by reportage at a respectable website!
https://www.spectrumnews.org/news/why-was-a-study-about-autism-cited-by-a-paper-on-plant-beauty/
LikeLike
I hope you appreciate that same Dalmeet S Chawla previously stole yours (and Tiger’s and Morty’s) credit for Chinese paper mill and gave it to Byrne and Christopher.
https://www.science.org/content/article/single-paper-mill-appears-have-churned-out-400-papers-sleuths-find
Imagine Ivan Oransky (Retraction Watch-dog and EiC of Spektrum) emailing back and forth with Chawla about how to steal your credit for this story, again. Our dear heroes of science journalism and ethics.
LikeLike
Pingback: Polymer Papermillers Taking the Piss – For Better Science
Pingback: [Citation not needed] – For Better Science
Pingback: Wiley: Committed to integrity? Get out! – For Better Science
Pingback: Cyclotron Branch, Before the Fall – For Better Science
Mass retractions today (12-Sept-2023) from the Cognitive Systems Research special issue you mention (vol. 52).
LikeLike