
Smut Clyde has a theory, and mind you, this is merely a theory, because we don’t want to raise or, worse, point fingers here, and this theory suggests that the papermills quite possibly may be fabricating papers about machine learning based of clinical datasets of very questionable provenance. Again, we don’t want to raise alarms or cry wolves and we definitely wish to avoid unnecessarily scaring the publishing industry, but it may look, from a certain angle in certain light, that these datasets are both fake and contain unethical human data stolen off the internet without the subjects’ consent.
The source here is the website Kaggle, self-advertised as “The World’s AI Proving Ground“.

Burt! This bloke won’t Kaggle!
by Smut Clyde
 Kaggle Rock was an expression of Jim Henson’s inspired creativity – a magical place where colourful tribes of muppets devoured one another’s architecture and consistently failed at communication, sometimes consulting Marjory the Trash Heap for advice (“a large, matronly, sentient compost heap”). No, wait, that was Fraggle Rock.
Kaggle Rock was an expression of Jim Henson’s inspired creativity – a magical place where colourful tribes of muppets devoured one another’s architecture and consistently failed at communication, sometimes consulting Marjory the Trash Heap for advice (“a large, matronly, sentient compost heap”). No, wait, that was Fraggle Rock.
Kaggle is part of the Open Science archipelago. It allows interested persons to announce Machine Learning (ML) challenges (often of a biomedical or clinical nature) in which contestants can enroll their digital-doctor ML frameworks, and to deposit the benchmark ‘data sets’ on which those contenders will be trained and tested. I wrap quote marks around ‘data’ because those benchmarks can be synthetic collections of images or symptoms and measurements, sourced from a simulation; they could also be purloined, with the intellectual-property identity-stamps filed off. It is also a Social Medium with its own internal attention-economy of Upvotes and Followers. Anyway, 100% muppet-free, amirite?
It is time for an illustration, so please admire these heliographs showing the sun at the peak of the sunspot cycle… HA HA not really, they are ‘fundus photographs’ showing the backs of eyes ravaged by diabetic retinopathy. When years of high blood glucose from poorly-controlled diabetes damages the blood vessels in your retinas, and colour vision goes kattywampus. We will come back to those, for diabetic retinopathy and fundus photographs are both popular in Kagsploitation – the fictional genre of interest today.
Yuqian Zhou, Shuhao Lu Discovering Abnormal Patches and Transformations of Diabetics Retinopathy in Big Fundus Collections Computer Science & Information Technology (2017) doi: 10.5121/csit.2017.70119

First, it is time for something completely different: an example that is not so easily illustrated. For back in 2019, a certain Gerald Piosenka – a retired engineer with a hobby and a deficient notion of what constitutes ‘creepy behaviour’ – scraped an archive of 2940 photographs of children from the Intertubes and deposited them in Kaggle, tagging half as ‘autistic’ and half as neurotypical. For he agreed with the common-sense opinion of the present US Secretary of Health and Human Services Robert F Kennedy Jr that ‘autistic’ and ‘funny-looking’ are interchangeable, and saw a need to automate the diagnostic process, so that the facial-recognition surveillance that’s already a pervasive feature of the State Panopticon could receive a software upgrade. Papermillers and editors alike found both assumptions irresistible: Calli McMurray at The Transmitter found 90+ papers and preprints pretending to have taught ML systems to assemble the subtle cues of physiognomy by training them on some version of Piosenka’s scrapbook. And retractions rained down like the hammer of Thor. Two examples:
- İbrahim Güngör , Abdullah Sarman , Suat Tuncay Can artificial intelligence and face recognition using deep learning detect emotions in children with autism? PLOS One (2025) doi: 10.1371/journal.pone.0338701 Retracted and removed December 2025.
- Tayyaba Farhat , Sheeraz Akram , Muhammad Rashid , Arfan Jaffar , Sohail Masood Bhatti , Muhammad Amjad Iqbal A deep learning-based ensemble for autism spectrum disorder diagnosis using facial images PLOS One (2025) doi: 10.1371/journal.pone.0321697 Retracted and removed December 2025.

“Some version”, because after the Kaggle archivists grudgingly took down his first scrapbook, he posted it on a G**gle drive; then other Collectors joined the game by cloning it on Kaggle (and other repositories, such as Mendeley) for their own challenges – sometimes augmented with their own stolen faces of even less provenance. Case in point: Cihan Senol‘s clone extended to 3,374 images. Before that in turn was taken down in an ongoing game of Whack-a-Mole (which sadly does not rhyme with Guacamole), it provided a pretext for Almars et al to train rival ML systems while digital gorillas optimised their hyperparameters… a display of cybernetic onanism that is currently weighed down by an Editorial Expression of Concern.
Abdulqader M. Almars, Mahmoud Badawy, Mostafa A. Elhosseini ASD2-TL∗ GTO: Autism spectrum disorders detection via transfer learning with gorilla troops optimizer framework Heliyon (2023) doi: 10.1016/j.heliyon.2023.e21530
“Post-publication, the journal was alerted to concerns regarding a dataset used in this study and cited via reference number 40. It has been reported that the dataset contains images of patients without autism spectrum disorder (ASD) diagnosis. In addition, there is no information about informed patient consent. The journal contacted the authors for clarification, and they stated that they were not aware of these concerns.
Additionally, the investigation conducted by the journal also identified potential issues in the use of Artificial Gorilla Troops Optimizer (GTO) in the study, as well as references that are irrelevant to the article. The authors were asked to provide an explanation, but the Editors were not fully satisfied with their response. Therefore, the Editors have decided to publish an Expression of Concern.”
(Expression of Concern, April 2026)
Given (1) the egregious ethical breach when none of the individuals or their families consented to the exploitation of their images, and (2) the worthlessness of any conclusions built on such undocumented labels, a mere Expression of Concern seems inadequate – the manuscript should have been desk-rejected directly into the editor’s circular filing cabinet, but that is not how the game is played. The most charitable interpretation is that Elsevier recognised the whole bag of words as a papermill product and thought: No analyses were actually performed, no ethics were violated; the whole thing is just an exploration of the architectural possibilities of bovine excrement as a construction material.
Almars et al. distinguished themselves from all the other flim-flam merchants by bringing in a second data-set: consisting of numbers rather than images, but somehow subjected to the same battery of image-classification algorithms. The numbers are True/False scores on (unspecified) behavioural questions, and do not include responses from Neurotypical controls, so any genuine peer-reviewers would have wondered what the authors were pretending to classify. The important part, though, is that after the Gorilla Troops had optimised the hyperparameters and eliminated some of those questions as redundant, the completely pointless calculations took much less time to reach their lack of results.

Bottom of the barrel: BatDolphin-based sparse fuzzy algorithm
“BatDolphin-based sparse fuzzy algorithm, cat swarm optimization, honey bees optimization, moth amalgamated elephant herding optimization, fitness sorted moth search algorithm, improved tunicate swarm optimization, lion algorithm, deer hunting optimization, various rider optimization schemes, grey wolf optimization, cuckoo search, and finally a bat algorithm. Such a zoo of names immediately raises suspicion, and for a good…
This is unedifying but illustrative on so many levels of how quickly papermills have parasitised the Open Science paradigm and strip-mined all its resources. It also illustrates how quickly the incantatory Worship Words of Machine Learning shut down the critical faculties of reviewers when included in a manuscript, convincing them that its ludicrous claims are merely restatements of what they already know.
Must credit those agitators who pressed publishers for the retraction of all papers that exploit Piosenka’s child-porn collection. I would also be calling for the resignation of every credulous incompetent who accepted one of these 90+ travesties of ‘research’, but the campaigners are better people. Or perhaps just more realistic.

Sticking to the stercorean theme of bovine byproducts, the next case-study repeatedly alludes to ‘farmwork’ rather than ‘framework’. A “Swin based vision transformer” learned to diagnose unspecified orthodontic diseases from x-ray photographs of successful root-canal fillings – helped by a hybrid optimiser adjusting its hyperparameters and selecting the best features. Published in Scientific Reports [of course]:
YuanYuan Chen , Zhi Jian Su , Rui Zhang , ShiLu Huang AI meets endodontics a deep learning approach to precision diagnosis Scientific Reports (2025) doi: 10.1038/s41598-025-26768-6
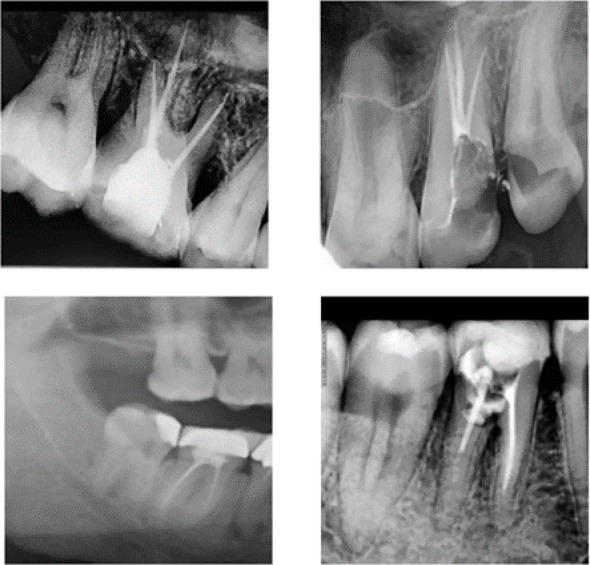
“The dataset used in the study of EDC is publicly available20 and its few samples are provided in Fig. 1.” … “The root canal data (RCD)20 on Kaggle is a public dataset of endodontics diagnostics and it can be valuable resource for benchmarking a DL architecture.”
Editors and reviewers were not concerned by the authors’ uncertainty about the corpus of x-rays they lied about using for training and performance testing. A Kaggle compilation is cited twice, and credited to an actual curator, but it does not exist in the time-line we inhabit. In contrast, the Data Availability statement cites an atlas of ‘panoramic’ dental x-rays that does exist but doesn’t match the root-canalled images – not in panoramic format! – shown as Figure 1.
A payload of nonsensical paid-for citation payola is the evidence that that none of this ever happened. It is one of the red flags of a papermill origin. Here and throughout the Kaggle-connected genre, there are enough red flags for a May Day parade in Beijing.

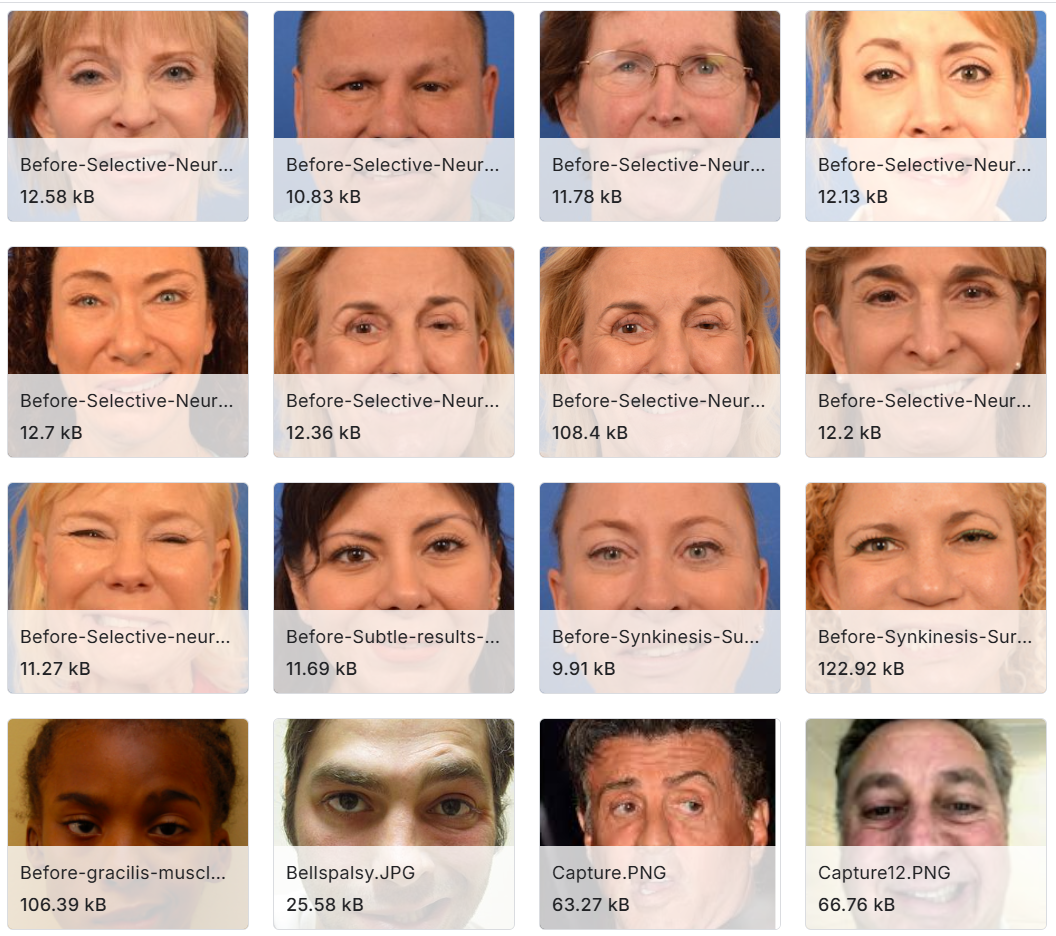 Clearly there is tough competition for ‘most ludicrous training material for machine learning’. It must be part of the Zeitschmerz, or the Weltgeist, or vice versa. Interviewed by Retraction Watch, Adrian Barnett made a strong case for awarding that coveted title to a compilation of 1024 “Stroke Faces” (“facial droop and facial paralysis“) that curator Kaitav Mehta “collected from google images” for “GAN image generation experiment”. There are duplicates, and random celebrities; a crying infant; photos labeled with non-stroke diagnoses like ‘Bell’s Palsy’ and ‘River Blindness’; even drawings. Refuting Mehta’s attempt to blame Image Search for the farrago, many were scraped systematically from some plastic surgeon’s ‘Before’ and ‘After’ webpages peddling Botox treatment and facial-nerve surgery. The insubstantial for-entertainment-purposes-only shonkiness of this foundation deterred neither millers nor editors, and a favela of paper-shaped shacks is even now sprouting upon it. Notably (because Scientific Reports) this: currently flagged with an Editor’s Note about raised concerns under investigation:
Clearly there is tough competition for ‘most ludicrous training material for machine learning’. It must be part of the Zeitschmerz, or the Weltgeist, or vice versa. Interviewed by Retraction Watch, Adrian Barnett made a strong case for awarding that coveted title to a compilation of 1024 “Stroke Faces” (“facial droop and facial paralysis“) that curator Kaitav Mehta “collected from google images” for “GAN image generation experiment”. There are duplicates, and random celebrities; a crying infant; photos labeled with non-stroke diagnoses like ‘Bell’s Palsy’ and ‘River Blindness’; even drawings. Refuting Mehta’s attempt to blame Image Search for the farrago, many were scraped systematically from some plastic surgeon’s ‘Before’ and ‘After’ webpages peddling Botox treatment and facial-nerve surgery. The insubstantial for-entertainment-purposes-only shonkiness of this foundation deterred neither millers nor editors, and a favela of paper-shaped shacks is even now sprouting upon it. Notably (because Scientific Reports) this: currently flagged with an Editor’s Note about raised concerns under investigation:
Alaa M. Mohamed , Hanan M. Amer , Asmaa H. Rabie , Ahmed I. Saleh , Mohy-Eldin A. Abo-Elsoud Real-time monitoring system for early stroke detection based on fog computing and enhanced deep learning techniques Scientific Reports (2025) doi: 10.1038/s41598-025-28513-5

 Mohamed et al 2025 is a Very Serious Paper. It invoked Fog Computing and the promise of 24-hour stroke surveillance to further dull any residual reviewer skepticism: thus no-one blinked when the authors switched mid-text from the droopy-face scrapbook to basing their fantasy on a different set of images. This new collection was pirated from an AI researcher’s GitHub repository, which is why it no longer exists on Kaggle, but it lingered there long enough to inspire at least two other dumpster fires:
Mohamed et al 2025 is a Very Serious Paper. It invoked Fog Computing and the promise of 24-hour stroke surveillance to further dull any residual reviewer skepticism: thus no-one blinked when the authors switched mid-text from the droopy-face scrapbook to basing their fantasy on a different set of images. This new collection was pirated from an AI researcher’s GitHub repository, which is why it no longer exists on Kaggle, but it lingered there long enough to inspire at least two other dumpster fires:
- Fadwa Alrowais , Mohammed Alqahtani , Jahangir Khan , Achraf Ben Miled , Da’ad Albalawneh , Abdulwhab Alkharashi , Samah Al Zanin , Radwa Marzouk Enhancing neurological disease diagnostics: fusion of deep transfer learning with optimization algorithm for acute brain stroke prediction using facial images Scientific Reports (2025) doi: 10.1038/s41598-025-97034-y
- Marta Narigina, Agris Vindecs , Dušanka Bošković , Yuri Merkuryev , Andrejs Romanovs AI-Powered Stroke Diagnosis System: Methodological Framework and Implementation Future Internet (2025) doi: 10.3390/fi17050204
The first paper received in May 2026 the same Editor’s Note. The second, from Riga Technical University in Latvia, didn’t receive any notes yet, because MDPI.
The real focus for Barnett’s medRXiv preprint from May 2026, Gibson et al 2026, was a pair of Kaggled clots of fake numbers – made-up clinical precursors to stroke, and to diabetes – that provided papermillers with grist to grind into a torrent of ML fiddle-faddle. Some people would argue that rather than pointing and laughing at this meretricious gossamer, we should take it very seriously, for already the Rumpelstiltskins of the second-order Literature Review papermills have seized the straw and are spinning it into gold Clinical Guidelines to be pipelined into practice. Fortunately I am not one of those people.
“Authors from 32 different countries developed clinical prediction models using either of the two datasets, assessed by the first author country affiliation.”
Alexander D Gibson, Nicole M White, Gary S Collins, Adrian G Barnett, Evidence of Unreliable Data and Poor Data Provenance in Clinical Prediction Model Research and Clinical Practice medRxiv (2026) doi: 10.64898/2026.02.24.26347028
The retractions are thundering down as if they’re auditioning for a role in Wagnerian opera:
“After publication, concerns were raised regarding the datasets used in this study [1]. The Authors relied on the publicly available datasets, the Stroke Prediction Dataset and the Diabetes Prediction Dataset, whose provenance and validity cannot be confirmed. As these datasets were used for the training and validation of the proposed model in this Article, the Editors no longer have confidence in the reliability of the results and conclusions of this Article.”
(Retraction, June 2026)

The Citation Payola
“The proposition that a niche of citation brokers exists, opens our eyes to other transaction options..” . Smut Clyde
Alternative title: Merely corroborative detail, intended to give artistic verisimilitude to an otherwise bald and unconvincing narrative
“Diabetes” is all the excuse I need to return to the topic of diabetic retinopathy. So alluring is the prospect of replacing trained ophthalmologists with software to turn fundus photographs into diagnoses of this condition, anyone playing at Science can receive a Participation Trophy from the familiar journals (Scientific Reports, Heliyon, IEEE, etc.). Here I single out three papers because of their shared ghost-writer authorship: the Reference sections of all three are adorned with overlapping payloads of nonsensical, transactional citations (as papermills resort to citation payola as a secondary income stream), all drawn from a single common pool.
- Fitsum Mesfin Dejene, Yehualashet Megersa Ayano, Degaga Wolde Feyisa , Taye Girma Debelee, Hiwot Taye Mekonnen , Girum Woldegebreal Gessesse , Zelalem Chimdesa Merga , Hasset Tamirat Molla , Destaw Mulie Knowledge distillation-based lightweight MobileNet model for diabetic retinopathy classification Scientific Reports (2025) doi: 10.1038/s41598-025-30893-7
- K. Suganya Devi , Hemanth Kumar Vasireddi , GNV Raja Reddy , Satish Kumar Satti Unfolding the diagnostic pipeline of diabetic retinopathy with artificial intelligence: A systematic review Survey of Ophthalmology (2025) doi: 10.1016/j.survophthal.2025.09.008
- Abdulwhab Alkharashi , Marwa Obayya , Muhammad Kashif Saeed , Ali Alqazzaz , Abdulsamad Yahya, Menwa Alshammeri , Donia Badawood , Samah Al Zanin GRIFD: a graded region-wise dissection and cross-pooling RNN framework for precise diabetic retinopathy detection in fundus images PeerJ Computer Science (2025) doi: 10.7717/peerj-cs.3197
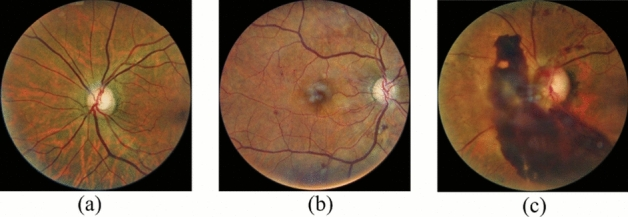
 Dejene et al 2025 refer the readers to a “APTOS 2019 Blindness Detection” Kaggle challenge for the source of their images: an archive of 3662 Fundus photographs, classified into the five levels of retinopathy severity. I hesitate to count all the software releases that trained on it, exceeded the accuracy of their precursors, were heralded in papers and conference reports, and sank straight into oblivion. All point to the public availability of the APTOS archive as one of its advantages; any of countless editors and reviewers could have checked this claim (and found it to be a lie) simply by clicking on the link. The images were only ever provided to entrants who’d accepted the conditions of the challenge that closed in 2019.
Dejene et al 2025 refer the readers to a “APTOS 2019 Blindness Detection” Kaggle challenge for the source of their images: an archive of 3662 Fundus photographs, classified into the five levels of retinopathy severity. I hesitate to count all the software releases that trained on it, exceeded the accuracy of their precursors, were heralded in papers and conference reports, and sank straight into oblivion. All point to the public availability of the APTOS archive as one of its advantages; any of countless editors and reviewers could have checked this claim (and found it to be a lie) simply by clicking on the link. The images were only ever provided to entrants who’d accepted the conditions of the challenge that closed in 2019.
Editorial laziness and incuriosity are becoming a theme. Jabbar et al 2022 claimed to have trained their system on images from a fundus-photography collection pooled across a US eye-care consortium (‘EyePACS’) for a 2015 Kaggle challenge:
“The public dataset EyePACS was used for acquiring fundus images of the retina via Kaggle.com (accessed on 24 March 2021).”
- Muhammad Kashif Jabbar, Jianzhuo Yan, Hongxia Xu, Zaka Ur Rehman, Ayesha Jabbar Transfer Learning-Based Model for Diabetic Retinopathy Diagnosis Using Retinal Images Brain Sciences (2022) doi: 10.3390/brainsci12050535
- Mohamed F Fath El-Bab , Nashaat Shawki , Ali AL-Sisi , Mohamed Akhtar Retinopathy and risk factors in diabetic patients from Al-Madinah Al-Munawarah in the Kingdom of Saudi Arabia Clinical ophthalmology (2012) doi: 10.2147/opth.s27363

 One minor problem was that the illustrative examples they showed were not from EyePACS. Jabbar et al 2022 had lifted them from a 2012 paper from Saudi ophthalmologists; either directly (mislabeling the severity levels because incompetence), or from Zhou & Lu 2017 (mentioned above) as an intermediary.
One minor problem was that the illustrative examples they showed were not from EyePACS. Jabbar et al 2022 had lifted them from a 2012 paper from Saudi ophthalmologists; either directly (mislabeling the severity levels because incompetence), or from Zhou & Lu 2017 (mentioned above) as an intermediary.
Perhaps more crucially, EyePACS images had never been publicly available; they were only accessed by contestants registered for the challenge, under rules that “do not allow sharing of the data outside of Kaggle”. There are of course a few bootleg versions, claiming to be pirated copies of the archive, if you don’t mind the uncertain origin and intellectual-property theft.
The authors’ contributions to the PubPeer thread broke new ground in mendacity, and featured the argument that the EyePACS / Kaggle images must have been accessible because papermills had already set a precedent by lying about accessing them (notably, Zhou & Lu). Jabbar et al. were vehemently, repeatedly insistent that their fundus images didn’t come from El-Bab et al., (2012), proposing that those authors were the thieves who stole their illustrations from the EyePACS compilation three years later.
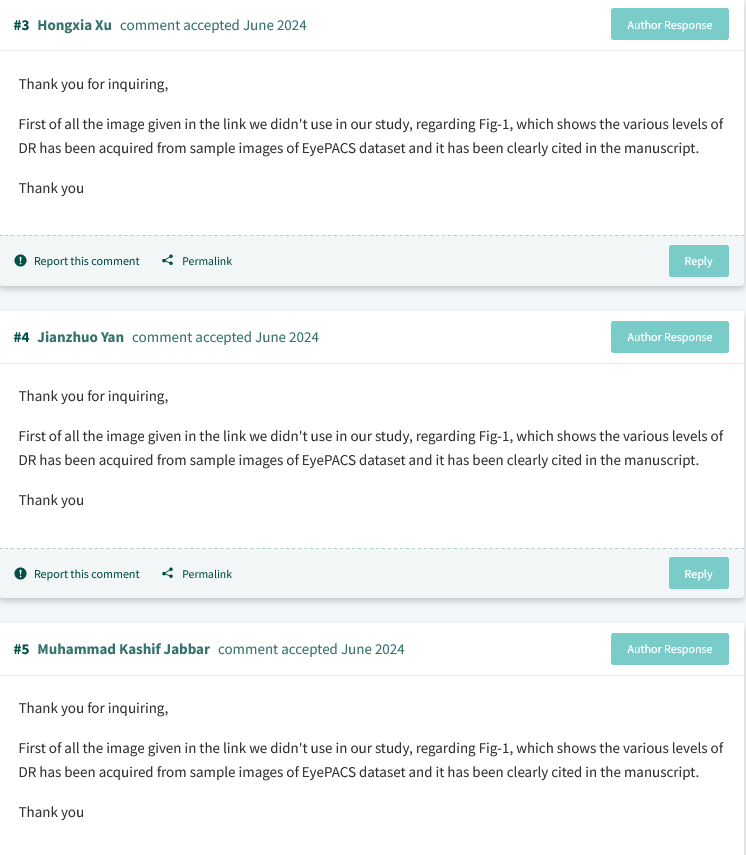
A few days later, in a July 2024 Correction, they rewrote the Figure legend behind the scenes and added a citation belatedly crediting El-Bab et al 2012 (“Figure 1 shows samples of NPDR, PDR, and its subdivided classes of retinopathy discussed above [11]“) . Shame on the Editors for conniving with this gaslight but MDPI have a reputation to live down to.
And in my haste I skipped over Alkharashi et al. 2025 – the third of the citation-spammed cases above. Those authors excelled themselves by offering three contradictory accounts of the data they fed into a customised recurrent Neural Network. Or five, depending how you count:
- “Data is available at Zenodo: Abdulsamad, Q. (2025). GRIFD: A Graded Region-Wise Dissection and Cross-Pooling RNN Framework for Precise Diabetic Retinopathy Detection in Fundus Images [Data set]. Zenodo. https://doi.org/10.5281/zenodo.16356982“ [there are no data in the Zenodo entry]
- “The study utilised a publicly available dataset from kaggle repository: https://www.kaggle.com/c/diabetic-retinopathy-detection/data.” [the unavailable EyePACS collection again]
- “The testing fundus image inputs are fetched from Akram et al. (2020) which contains 100+ fundus images of patients between 25 and 80 years of age. The digital image resolution is 1,500×1,000 pixels of which 76 are infected [sic] with DR.” … “The dataset for the current study comprises more than 100 colour fundus images from the Mendeley Data repository (Akram et al., 2020), which contain various retinal conditions, including diabetic retinopathy. A total of 100 images were manually examined and selected for training and testing, 24 normal, 28 mild DR and 48 severe DR—a balance across the spectrum of severity.” [The Akram / Mendeley data-set does indeed consist of 100 fundus photographs, but that’s the only resemblance to this hallucinatory description]
 There is nothing new about this. Muthu BalaAnand excelled in lending verisimilitude to his
There is nothing new about this. Muthu BalaAnand excelled in lending verisimilitude to his bald and unconvincing narratives fraudiness by exploiting data from research that (if it happened) was never available. Even in that generation of papermillers, diabetic retinopathy was flypaper for fabrication, see on the right Gunasekaran Manogaran‘s Krishnamoorthy et al 2021.

Research on Intelligent Trash Can Garbage Classification Scheme
“It’s not as if the Special-Issue Guest Editors or the imaginary ‘Peer Reviewers’ pay attention to the provenance of the images that fill the Figure-shaped gaps, or care whether the supposed alternatives in these horse-races are even algorithms at all.” – Smut Clyde
Much more Fundus-Photography / ML fiddle-faddle is out there (and even a few retractions, like Bilal et al PLOS One 2024), but bored now. It is time to follow the spoor of the papermillers as they progressed to other AI tasks. Several pimped-out ‘citation magnets’ provide leads, but I found it especially instructive to ask who is citing “White patchy skin lesion classification using feature enhancement and interaction transformer module“? One answer to that question involved colouring within lines marking the boundaries of brain tumours (gliomas) within MRI scans.
Here the relevant benchmark is the Brain Tumor Segmentation Challenge, ‘BraTS 2023‘, which is too classy for Kaggle and the files are housed instead at Synapse.org (a branch of Sage). The challenge organisers provide access to identified users, on request, subject to attribution and citation conditions.

So the Editors of Gao et al. realised at once from the absence of such acknowledgements, and from the absurdly counterfactual claim that “we used BraTS 2023 dataset … publicly available on platforms like Kaggle and The Cancer Imaging Archive”, that the author knew nothing about the nature of the data; and that the figures given for network performance are just aspirational Artist’s Renditions of what results might look like if the proposed architecture were actually put into practice… HA HA of course not. It is not the concern of a Scientific Reports editor that the numbers in a manuscript are fabricated, as long as the value paid to the publisher is correct.
Yan Gao Smart IoT with the hybrid evolutionary method and image processing for tumor detection Scientific Reports (2025) doi: 10.1038/s41598-025-16042-0

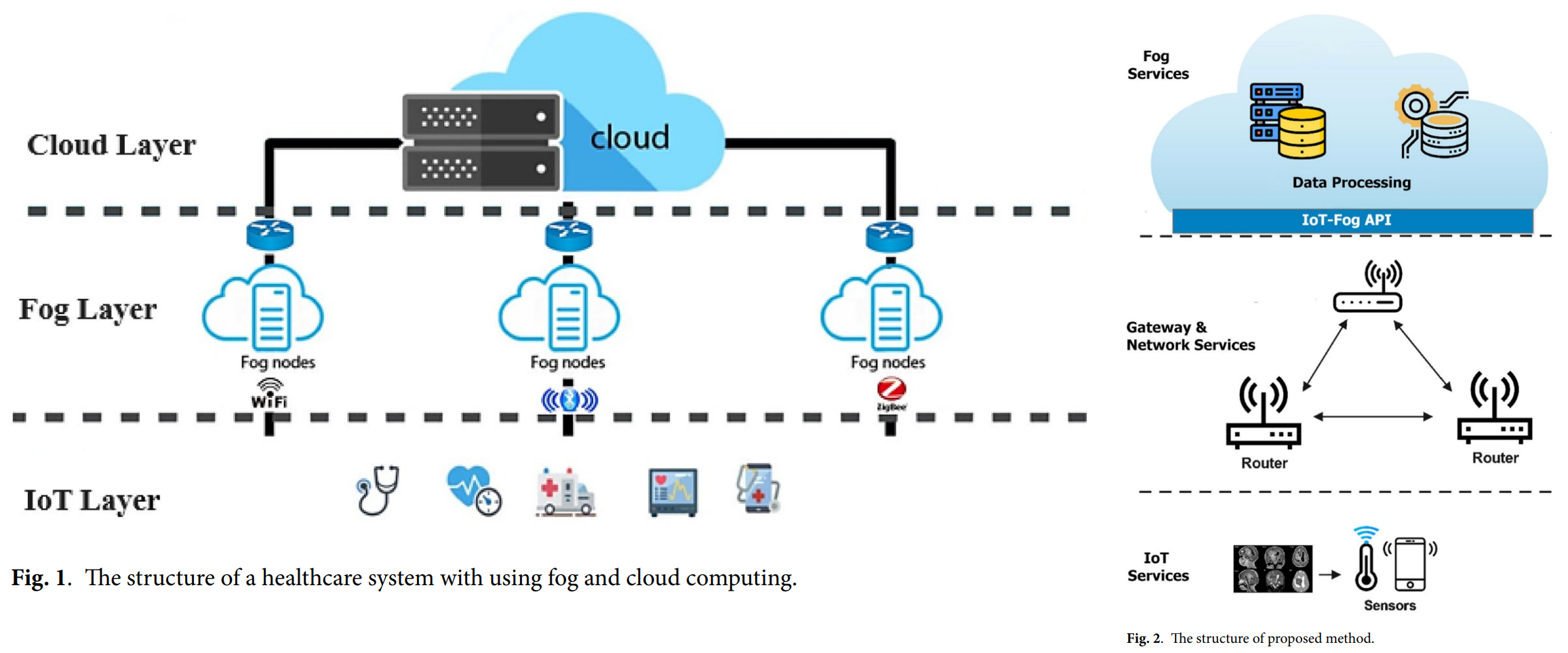
Brain-tumour diagnostics were too easy for Gao, and the paper is an obfuscated gallimaufry of metaheuristic optimiser algorithms fine-tuning a Convolutional Neural Net – all distributed across the nodes of the Internet of Gadgets to make it more challenging. Tumour segmentation is merely an application of the Fog Computing Paradigm, because a high-resolution high-Tesla fMRI scanner is equivalent to a wearable IoMT blood pressure sensor. No, really.
“Numerous medical Internet of Things devices, like wearable monitors or portable diagnostic sensors, function in energy-constrained settings where it is impractical to replace or recharge batteries frequently, particularly in disaster areas, mobile health units, and rural clinics. HETS-IP contributes to increased system reliability and operational sustainability…”
Along the trail of “White patchy skin lesion classification” citation spam we also encounter Ahmad et al 2025, and ML for mammography. A comparison of their text to LLM output prompted those authors to respond on PubPeer by asking a LLM to write a wall-of-text. Their explanation of how a paper on mammography (which is done with X-rays) might be illustrated with ultrasound imagery was “We forgot”.
Sultan Ahmad, Eali Stephen Neal Joshua, Nakka Thirupathi Rao, Rania M. Ghoniem , Belayneh Matebie Taye, Salil Bharany A multi stage deep learning model for accurate segmentation and classification of breast lesions in mammography Scientific Reports (2025) doi: 10.1038/s41598-025-21146-8

“We forgot” was also the reason for the failure to properly cite the CBIS-DDSM mammography dataset, as is firmly demanded as part of the ‘Data Policy Usage and Restrictions’. “We stole the data legitimately“, on other words… though “We never so much as glanced at the images” is more parsimonious. We only know for sure that the Editor never so much as glanced at the supposed data source.

I will go out on a limb here to predict that there are many other paper-shaped artefacts stinking up the literature, announcing incremental progress in segmenting tumours within the CBIS-DDSM and BraTS 2023 datasets, but the search for them is left as an exercise for the reader. Suffice to say that Jabbar et al. (2023) claimed to have used the BraTS 2019 and 2020 datasets but of course they lied.
Ayesha Jabbar , Shahid Naseem , Tariq Mahmood , Tanzila Saba , Faten S. Alamri, Amjad Rehman Brain Tumor Detection and Multi-Grade Segmentation Through Hybrid Caps-VGGNet Model IEEE Access (2023) doi: 10.1109/access.2023.3289224

If anything, the situation is worse than as reported in Barnett’s preprint. The unconstructive, no-effort combinatorial treatments of freely-available (though information-free) datasets, spilling out from computational pipelines, are only one of the invasive species transforming the academic ecosystem into a monoculture of slop. Those pointless Glass-Bead-Game exercises are outnumbered by papermill products where no time was wasted in accessing datasets at all; why bother when there are random-number generators, and editors and reviewers never check?

Shake the Stupid Tree and see what falls out
“Does this mean it’s time for an update on the bogus-citation economy? Leonid thought it is, and now you all must suffer for his misdirected priorities. ” – Smut Clyde
Alternative title #2: Θάλαττα! θάλαττα!
Who knew that Punjab Province (Pakistan) is home to zombies and the victims of vampirism, in roughly equal numbers? So it would seem from this closing basket of bobbins. It is a crazier story than the stroke-face scrapbook!
Some background first. α- and β- thalassaemia are forms of anaemia, caused by mutations in the genes that code for the α and β components of the haemoglobin molecule (or tetramer). If you’re only a heterozygous carrier for the condition, with one functional copy of the affected gene, you might not notice any problem (and you might have some resistance to malaria)… but you’ll pass the gene on to about 50% of children, and you don’t want to pair up with another carrier because any child has a 25% risk of being homozygous. So Punjab Province has a policy of testing people for the mutant genes; counselling carriers about this risk; and inviting the relatives of any carriers to get tested as well, in a snowball approach to recruitment.
Money and time could be saved if the presence of the mutation(s) could inferred from simple blood-work indicators like corpuscle-count, haematocrit, and so on – rather than DNA tests or liquid chromatography. Thus we encounter a genre of Machine-Learning fiction promising to perform this wizardry; and the inevitable Kaggled datasets they were purportedly trained on.
- Muhammad Umar Nasir , Muhammad Zubair , Muhammad Tahir Naseem , Tariq Shahzad , Ahmed Saeed , Khan Muhammad Adnan, Amir H. Gandomi Multiclass classification of thalassemia types using complete blood count and HPLC data with machine learning Scientific Reports (2025) doi: 10.1038/s41598-025-06594-6
- Muhammad Umar Nasir , Muhammad Tahir Naseem , Taher M. Ghazal , Muhammad Zubair , Oualid Ali , Sagheer Abbas , Munir Ahmad , Khan Muhammad Adnan A comprehensive case study of deep learning on the detection of alpha thalassemia and beta thalassemia using public and private datasets Scientific Reports (2025) doi: 10.1038/s41598-025-97353-0
- Maria Abbas , Muhammad Bilal Shoaib Khan , Abdul Hannan Khan , Anas Bilal , Asaad Algarni , Raheem Sarwar Interpretable machine learning models for beta thalassemia prediction: an explainable AI approach for smart healthcare 5.0 Frontiers in Medicine (2026) doi: 10.3389/fmed.2025.1688645
- Hafiz Ali Younas , Bilal Shoaib Khan , Abdul Hannan Khan , Anas Bilal , Asaad Algarni , Raheem Sarwar , Seyed Jalaleddin Mousavirad Prediction of β-thalassemia carrier using federated learning and explainable AI Frontiers in Medicine (2026) doi: 10.3389/fmed.2026.1687773
- Saima Sadiq , Muhammad Usman Khalid , Mui-Zzud-Din , Saleem Ullah , Waqar Aslam , Arif Mehmood, Gyu Sang Choi, Byung-Won On Classification of β-Thalassemia Carriers From Red Blood Cell Indices Using Ensemble Classifier IEEE Access (2021) doi: 10.1109/access.2021.3066782
- Furqan Rustam , Imran Ashraf, Shehbaz Jabbar , Kilian Tutusaus , Cristina Mazas , Alina Eugenia Pascual Barrera , Isabel De La Torre Diez Prediction of [Formula: see text]-Thalassemia carriers using complete blood count features Scientific Reports (2022) doi: 10.1038/s41598-022-22011-8
It is unclear whether Nasir et al 2025a (first paper in the list) based their impressive results on actual data or a simulated set [to the journal it is all the same]. They state authoritatively:
“The dataset of the proposed model was collected from the Punjab Thalassemia Prevention Program (PTPP) in Pakistan. […] The records in the dataset include 9987 individuals who are alpha thalassemia carriers through HPLC testing; 11,000 beta-thalassemia carriers diagnosed through HPLC testing; 10,060 alpha thalassemia patients identified through CBC testing; and 9981 beta-thalassemia patients diagnosed through the CBC testing.”
That is, half the records have a gold-standard diagnosis from HPLC = liquid chromatography, and half were diagnosed through CBC = Complete Blood Count, using calculations that the paper itself purportedly creates.
This is outweighed by the “all made up” side of the scales, where the authors refer to their ‘proposed model’, and describe it in aspirational terms (“The data will be collected from different hospitals“), while the Data Availability declaration offers to provide “The data generated and analysed in the current study”. What they do not state includes:
- how they gained access to PTPP records;
- why they are so cavalier about passing them on to anyone who asks;
- whether the beneficiaries of PTPP screening gave informed consent to have their records available to random researchers;
- whether ethical approval was sought and granted at any point;
- how participant confidentiality was preserved.
 More to the point, their summary of results for the HPLC figures show none of the correlations that one might expect. Hb, RBC, HCT, MCV, MCH, MCHC: these all measure haemoglobin level in different ways, and should be correlated. While HbA, HbA2, HbF give the clinical diagnosis of thalassaemia, and since they don’t correlate with any of the CBC scores then Nasir et al. are just wasting our time.
More to the point, their summary of results for the HPLC figures show none of the correlations that one might expect. Hb, RBC, HCT, MCV, MCH, MCHC: these all measure haemoglobin level in different ways, and should be correlated. While HbA, HbA2, HbF give the clinical diagnosis of thalassaemia, and since they don’t correlate with any of the CBC scores then Nasir et al. are just wasting our time.
In Nasir et al. 2025b (second in the list above), our authors confine themselves to the second set of made-up data from their first paper (without citing it) – “The record of 10,060 alpha thalassemia patients who are diagnosed after the CBC test and 9,981 beta thalassemia patients who are diagnosed after the CBC test” – however, they throw different bowls of ML spaghetti at the wall to see which sticks best. Details of the fictional PTPP source remain veiled in mystery, but we do learn now that “This study was approved by the Ethics committee of Riphah International University, Pakistan. Informed consent was obtained from all subjects.” No Approval reference code.
Nasir et al. further claim to validate their algorithm by applying it to two “Public datasets … sourced from medical databases“. Which does sound classier than Kaggle and GitHub.
- [39] Kolambage, N. Alpha Thalassemia Dataset-Carriers Vs Normal, Accessed [02 September 2024] https://www.kaggle.com/datasets/letslive/alpha-thalassemia-dataset
- [40] Mahnoor Analyzing Thalassemia with ML, Accessed [ 02 September 2024] https://github.com/mahnoor-dotcom/analyzing-thalassemia-with-ML/blob/main/IDA_BTT.csv
Neither collection has any reliable provenance. The second boasts 250 rows – each identified by a first name – and was deposited by Mah Noor, “Expert in Thesis Writing and Academic Research” (i.e. an academic ghostwriter looking for commissions). Noor evidently asked a LLM what a file of CDC data should look like in order to fool customers that it was genuine, and pasted its response into the accompanying explanatory readme file:

It is hilarious that someone would do this, which is why I go into so much detail. The search for other papers building their analytical castles on this swampy fabulation are left as another exercise for the readers, for we must move on!
Abbas et al 2026 and Younas et al 2026 were both submitted to Frontiers in Medicine at about the same time, albeit to different Special Issues. After the first authors, the authorship lists are largely the same. The name or obvious anagram Anas Bilal springs out – a frequent papermill customer (or papermiller), and impresario of this whole approach of computational codswallop, not a stranger to PubPeer. Neither paper admits the other’s existence, which seems odd, given that both analyse the same data set with the same goals (i.e. they throw bowls of ML spaghetti at the wall to see which sticks best). You’d think that one algorithm was superior, removing the point of publishing whichever paper didn’t report it.

So the data were the same (modulo different colour-schemes for the correlation heat-maps and different bin-width settings for displaying the distribution histograms). Abbas et al identified the source first as “real-world clinical data sourced from Kaggle“, and then “The dataset is collected from the database of Punjab Thalassemia Prevention Program (PTPP) that comprises 5066 data samples and 12 features for beta thalassemia prediction from the Punjab province of Pakistan (40, 61)” – i.e. the present Sadiq et al 2021 and Rustam et al. 2022:
- 40. Sadiq S, Khalid MU, Ullah S, Aslam W, Mehmood A, Choi GS, et al. Classification of β-thalassemia carriers from red blood cell indices using ensemble classifier. IEEE Access. (2021) 9:45528–38. doi: 10.1109/ACCESS.2021.3066782
- 61. Rustam F, Ashraf I, Jabbar S, Tutusaus K, Mazas C, Barrera AEP, et al. Prediction of β-Thalassemia carriers using complete blood count features. Sci Rep. (2022) 12:19999. doi: 10.1038/s41598-022-22011-8
 Younas et al put it this way: “The human samples used in this study were acquired from previously published articles with the following DOI’s “10.1038/s41598-022-22011-8” and
Younas et al put it this way: “The human samples used in this study were acquired from previously published articles with the following DOI’s “10.1038/s41598-022-22011-8” and
“10.1109/ACCESS.2021.3066782”. Which is to say, Sadiq et al and Rustam et al again. The claim is ironic (to have taken personal medical records from non-public archives without bothering with consent from the individuals identified in them), as Younas et al make a great tohu-bohu about the sacred nature of data confidentiality, and the need for Federated Learning to preserve it when outsourcing computations to the Fog. It is also a lie: neither primary ‘source’ provides data.
Somehow it became part of the papermill catechism that the way to keep information private is not to analyse it on a centralised air-gapped repository, but rather to invoke Federated Learning and distribute both data and analysis across an ephemeral network of insecure resources. Any manuscripts that omit that shibboleth risk the risk of rejection for their disturbing lack of faith. Anyway, let us proceed to those primary non-sources.
According to Sadiq et al, “In this research a novel dataset is collected from the database of Punjab Thalassaemia Prevention Programme (PTPP). […] In this study, the record of 5066 patients tested in 2019 is taken.” Those authors do not state how or by whom they were granted access to personal health records for identified individuals. Questions of “participants’ confidentiality” and “consent” and “ethical approval” never occur to them, nor to the journal’s editors and reviewers.
Rustam et al. inform us that “The dataset used in this research is collected from the database of PTPP” (with a link to Sadiq et al.) – though again no explanation of how they gained entrée to PTPP records. Under Data Availability they declare that “The dataset is not publicly available“, and in their concern for patient confidentiality they offer to share it with interested readers anyway. We do read that “All experimental protocols were approved by a Sheikh Zayed Hospital, Rahim Yar Khan, Pakistan“, which leads one to wonder what experiments occurred.

Hear her laughing in earthquake land
“For that marketplace is a labyrinth as large as the academic world, and the Ariadnean thread that traces the path back out of its interior seems to sprout subsidiary threads that lead into plant-based green nanoparticle synthesis or some other side-alley of parascience.” – Smut Clyde
Reconstructing the sequence of events,
- Sadiq et al chose to adorn their CVs with some invented results in the Thalassemia / ML intersection so they told a porkie about accessing the data of PTPP participants.
- Rustam et al. were too lazy to fabricate their own mythical data so they pretended to reuse the earlier set, confident that Sadiq et al. would not call them out on the lie.
- Abbas et al and Younas et al ran with the story. Suffice to say that there is no link for the Kaggle data-source they cite. Nevertheless they present the previously-lacking data distributions – building a fictitious Pelion upon the fabricated Ossa (or vice versa). In the manner of Borges’ hrönir, perhaps future papers will reverse-engineer the actual data. It is a tribute to the process of cultural creativity and the human need for backstory details, much as Science Fiction franchises spawn fan-fiction and the Christian mythos spawned the Golden Legend.
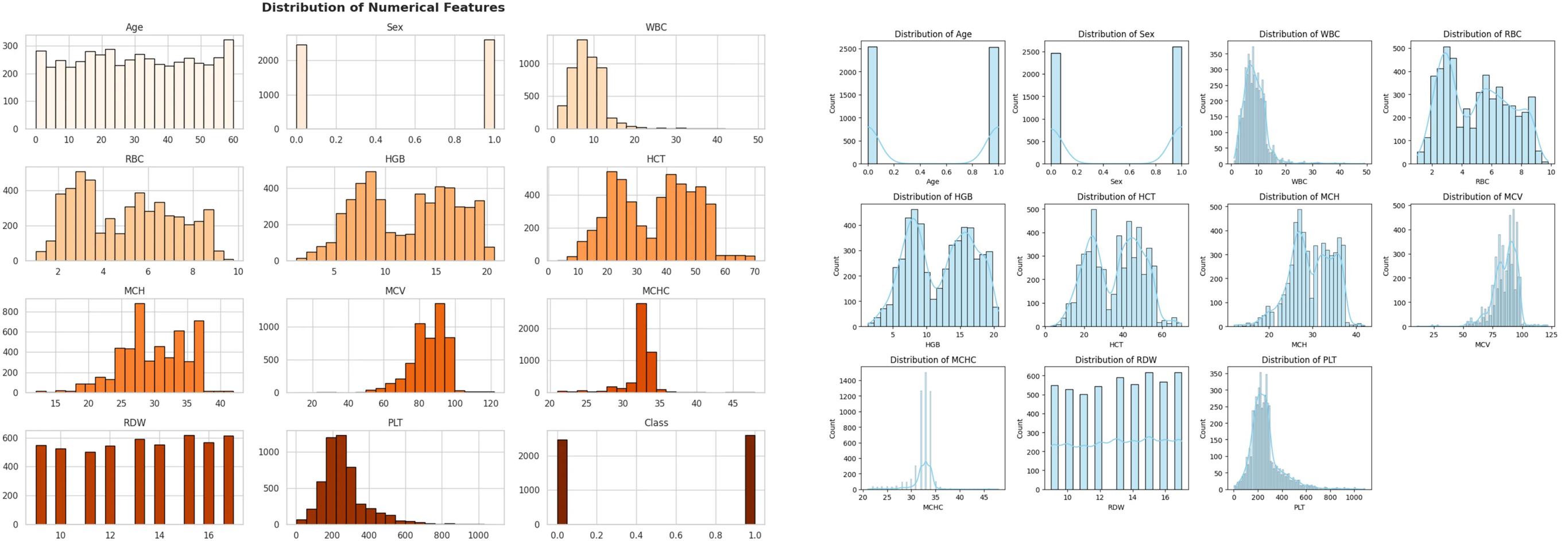
A feature of those distributions is the polarised bimodality of RBC, Hemoglobin and Hemocrit. It seems that half the screened population (thalassemia carriers?) were anaemic… or rather, so exsanguinated that they would no longer bother to breath. Meanwhile the non-carrier half were afflicted with such extreme polycythemia that their blood was too viscous to flow through capillaries, so they were also dead. While a flat distribution for RDW makes no sense.
In the PubPeer thread for Abbas et al, the commenter Salvia verbenaca called attention to a Kaggle archive of Thalassemia CBC results from India that was not the source of the data searched for here, as (1) there were 13000 cases, and (2) the distributions were very much not bimodal.

Crunchy Frog and Cockroach Cluster
“On one side: late-career scientists resorting to purchased promotion of their early-career papers. On the other side: whole new genres of paper-shaped artifacts that are little more than packaging for ever-larger citation cargoes, and papermillers no longer bothering to find buyers for naming rights on their products.” – Smut Clyde
Coda – Back to Autism. Also, more Diabetic Retinopathy!
Oh hi again Anas Bilal, hi Muhammad Kashif and Ayesha Jabbar, I was going to introduce you to my friend Retraction, but I see that you’ve already met.
Ayesha Jabbar , Huang Jianjun, Muhammad Kashif Jabbar , Khalil Ur Rehman , Anas Bilal Spectral feature modeling with graph signal processing for brain connectivity in autism spectrum disorder Scientific Reports (2025) doi: 10.1038/s41598-025-06489-6
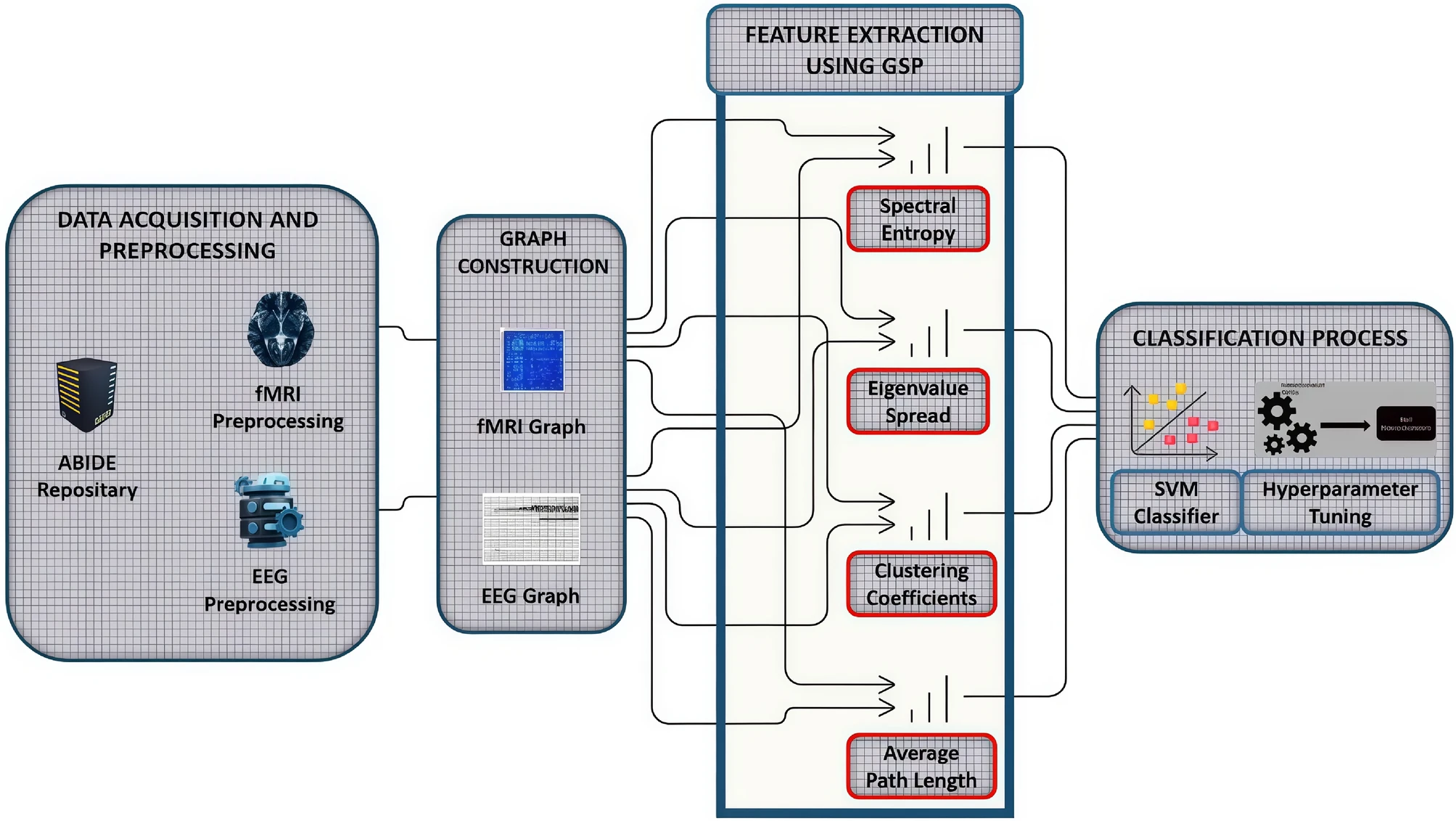
The Kaggled fMRI Dataset on Emotion contains a Training and a Test directory, each containing five emotions (afraid, calm, delighted, depressed, excited) and a few hundred brain slices for each. There is, I assume, a single subject, at a single time, with no measures of functional connectivity. In Jabbar et al this underwent a miraculous transmutation:
“The fMRI dataset was obtained from the fMRI Dataset on Emotion, consisting of resting-state scans from a 3 Tesla MRI scanner (TR = 2000 ms, 300 time points per subject) with functional connectivity mapped across 90 brain regions defined by the Automated Anatomical Labeling (AAL) atlas.”
Also via Kaggle, the EEG Brainwave Dataset: Feeling Emotions is described as follows: “The data was collected from two people (1 male, 1 female) for 3 minutes per state – positive, neutral, negative. We used a Muse EEG headband which recorded the TP9, AF7, AF8 and TP10 EEG placements via dry electrodes.” In Jabbar et al this was transformed into
“The EEG dataset was sourced from the EEG Brainwave Dataset on Feeling Emotions, containing recordings of emotion-related brain electrical activity suitable for capturing short-term dynamic changes. The final dataset comprised 80 participants, including 40 ASD subjects and 40 matched controls, ensuring a balanced sample that enables the classification model to learn without bias from class imbalance.”
Everything reported was a speculative vision of the results that the authors imagined might emerge if their vague hand-wavy schematic diagram had been fleshed out to the extent of being implementable, and then applied to non-fantasy data. Anyone at the journal could have clicked on a link and seen that the contents of the repository occupy a different plane of existence from the data described in the analysis, but “Editorial laziness” is already established as a theme.
The retraction from May 2026 stated:
“After publication, concerns were raised that some of the analyses reported had not been performed on the datasets listed in the paper. Source of fMRI data contains only static images making the assessment of functional connectivity not possible, and the source of EEG data does not contain enough observations or all the features necessary for the analyses described. Additionally, the sample size reporting is inconsistent throughout. The Editors therefore no longer have confidence in the results and claims of this Article.”
Meanwhile, Ayesha Jabbar made up more EyePACS analyses. PRO-TIP: Read the responses to your LLM prompts before copy-pasting them into your manuscript.
Ayesha Jabbar , Hannan Bin Liaqat , Aftab Akram , Muhammad Usman Sana , Irma Domínguez Azpíroz , Isabel De La Torre Diez , Imran Ashraf A Lesion-Based Diabetic Retinopathy Detection Through Hybrid Deep Learning Model IEEE Access (2024) doi: 10.1109/access.2024.3373467

And thanks to Scientific Reports, we can read how Jabbar & Jabbar educated a ML system to diagnose strabismus (or possibly retinal detachment), using a combination of (a) imaginary eye-tracking data and (b) even more “ludicrous training material for machine learning” than Mehta’s Droopy Stroke-Face scrapbook.
Ayesha Jabbar , Muhammad Kashif Jabbar , Tariq Mahmood , Yasin Ul Haq , Tahani Jaser Alahmadi , Haitham Nobanee , Amjad Rehman A retinal detachment based strabismus detection through FEDCNN Scientific Reports (2024) doi: 10.1038/s41598-024-72919-6
Coda #2
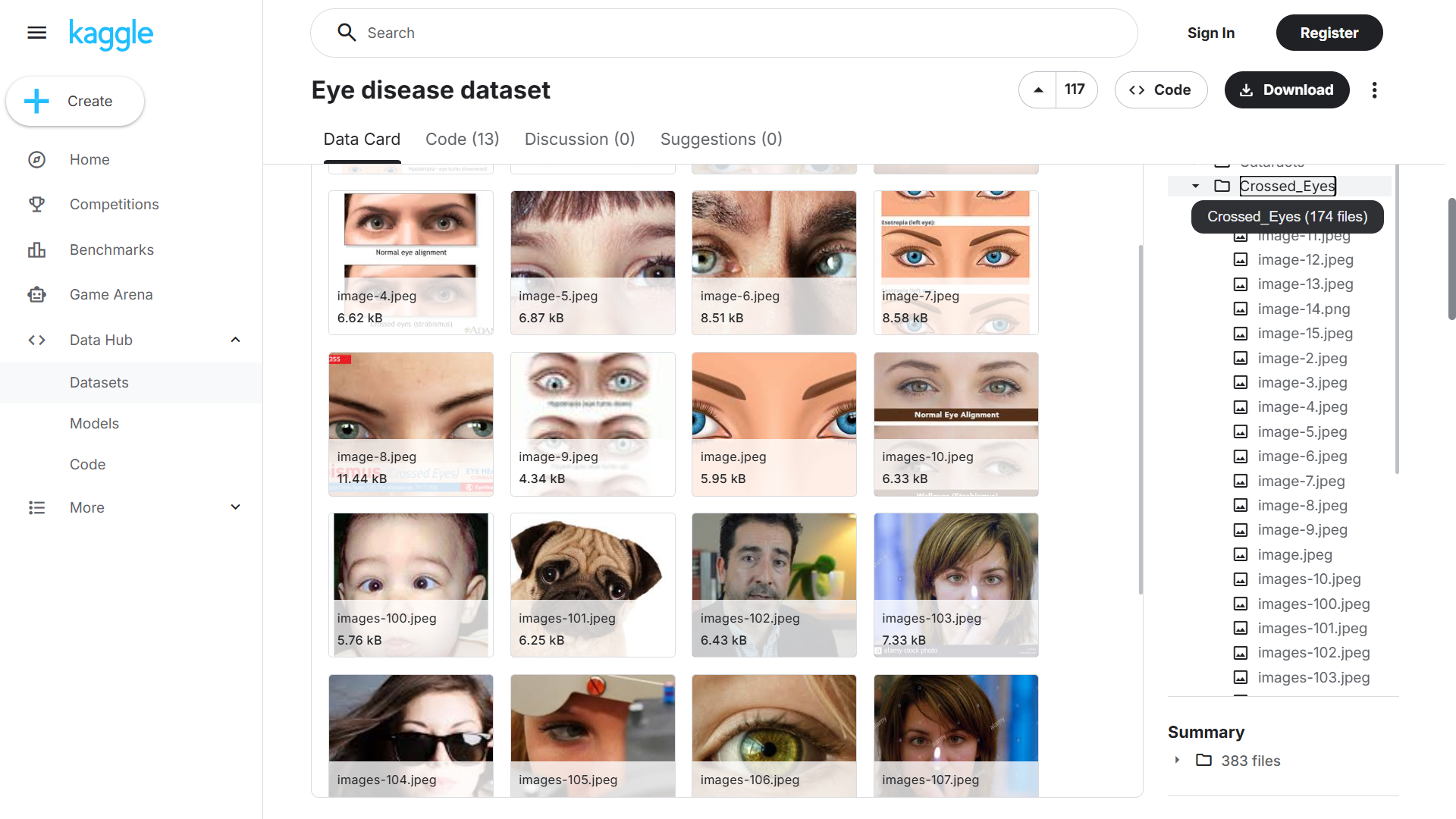
Güngör et al 2025 were not well-pleased at the unfairness of having their PLOS One paper retracted (see back at the start); for they are busy people, who cannot be expected to bother themselves about the validity (let alone the moral status) of every random child-porn collection they find useful.
“All authors responded stating that the use of the Kaggle datasets was a decision made in good faith, relying on what they considered to be the standard practice in the field of AI and Computer Science, and that they were unaware of the issues with the datasets.”
December 2025 Retraction
Arguably they are correct about appropriation, exploitation and fraud being “standard practice in the field of AI and Computer Science”.
Not everyone laughed when I wrote ‘Kagsploitation’ earlier so I’ll write it again.

Donate to Smut Clyde!
If you liked Smut Clyde’s work, you can leave here a small tip of 10 NZD (USD 7). Or several of small tips, just increase the amount as you like (2x=NZD 20; 5x=NZD 50). Your donation will go straight to Smut Clyde’s beer fund.
NZ$10.00


I am struck by the pointless nature of it all. Crediting the thoroughly dislikeable Iona Cristea with an obvious insight which hadn’t really occured to me, but this is the ultimate consequence of reviewers not being asked to assess the novelty of a paper. Now the literature is increasingly made up of short technical reports of brainless activities. Many turn out to be fraudulent. Still don’t know what the solution is. This approach of focusing on the data source seems like a much more productive angle than analysing the content of papers which I find thoroughly confusing.
LikeLike
Kaggle has been flagged by retraction watch and we have the data now visible on biomed resource watch. See warning to authors at the bottom of the page.
n2t.net/RRID:SCR_013852
LikeLiked by 1 person
Dear Leonid, probably you have heard, thanks to your job : https://www.sciencewatch.pl/551-osobliwa-sztafeta-pokolen-kolejny-krok-do-deprecjacji-tytulu-doktora-honoris-causa-i-polskiej-nauki
LikeLiked by 1 person
I don’t know if it’s wise to criticize Legutko. His mentee Krolczyk has now access to air-to-ground missiles and glide bombs.
LikeLike
If his piloting skills is on par with his research, then we’re safe.
LikeLiked by 1 person