
The Canadian shooting star of behavioural ecology Jonathan Pruitt used to be everyone’s best friend. Up until his co-authors accused the spider researcher of data manipulation and achieved retractions for 3 of his papers. His reputation in tatters, his research record facing even more retractions, his elite funding as one of Canada’s “150 Research Chairs” and prestigious job at McMaster University in danger, Pruitt did what every red-blooded academic in his position does: he deployed lawyers against his critics.
As Science reported, the lawyer’s letter was so scary that some journal editors panicked and hid under their tables, waving a white flag of surrender. No more Pruitt retractions unless specifically requested by the ongoing investigation at McMaster, no matter what the evidence submitted by co-authors proves.

The original recipients however, all of them former Pruitt co-authors, are not complying, they continue vetting Pruitt’s publications for further irregularities. As I learned, nobody signed anything or announced to adhere to any of lawyer’s demands. And why should they be afraid, the lawyer’s letter is not even really threatening anyone. It is a cack-handed attempt in intimidation which even Pruitt now apparently distances himself from.
All the letter from Millard and Company does, is to educate its recipient that nobody is supposed to be scrutinising Pruitt’s papers but his employer McMaster University, and that every retraction must be agreed by the Committee on Publication Ethics (COPE, a scholarly publisher lobbyist), whose advisory guidelines to its member journals are presented by Pruitt’s lawyers as a kind of a law for breaking of which you might end up in prison.
The letter is labelled “PRIVATE & CONFIDENTIAL WITHOUT PREJUDICE”, which is exactly why I publish it here in full, below. I hope the Millard lawyers are happy with this arrangement.
The Pruitt case made international news, it even got its own hashtag n Twitter: #PruittData. The communal effort to uncover data irregularities began with Kate Laskowski, now assistant professor at UC Davis in USA. Laskowski told the story on her blog, and it might explain the success recipe of Pruitt: when he met some scientist with an unproven pet theory, he provided them with the perfect experimental data. Which now proved to have been too good to be true.
In science, many beautifully designed theories collapse on experimental reality. Biology is very messy, complicated and rarely does as told, even and especially when the theory which biology is expected to adhere to is clever, beautiful and elegant, of the kind the editors in elite journals love and the research funders cherish. Which is exactly why so many scientists resort to research fraud, to force scientific reality to adhere to their theories.
Laskowski, then a PhD student, had a theory about animal behaviour in social context. She met at a conference the young shooting star Pruitt, who works with social spiders. Pruitt generously offered his collaboration, and soon perfect data arrived which perfectly proved Laskowski’s theory right. Pruitt’s datasets served as template for 3 papers in respectable journals, until someone contacted Laskowski with concerns. That colleague was Niels Dingemanse, professor at the LMU Munich in Germany, and he noticed there were statistically too many duplicate numbers in the paper’s publicly available original data file.
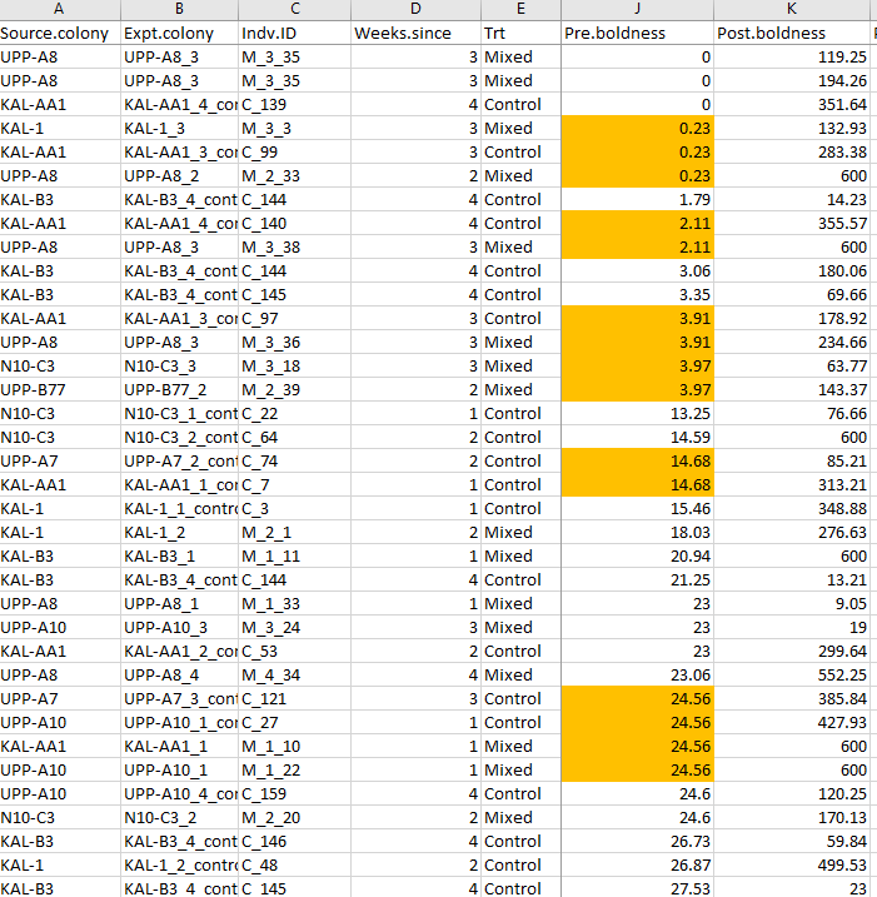
Thus alerted, Laskowski started to go through Pruitt’s Excel files, and indeed found many repetitive numbers. Pruitt was quick with an explanation, which sounded a bit weird, but it kind of sufficed to consider a correction. But then Laskowski analysed the files in more details and found entire strings of numbers repeating themselves, with the only logical explanation that they were made up. Once Laskowski removed all repetitive numbers, the remaining ones showed no significant difference in spider behaviour between experimental treatments. Her theory collapsed, so Laskowski had her own three papers retracted, one by one.
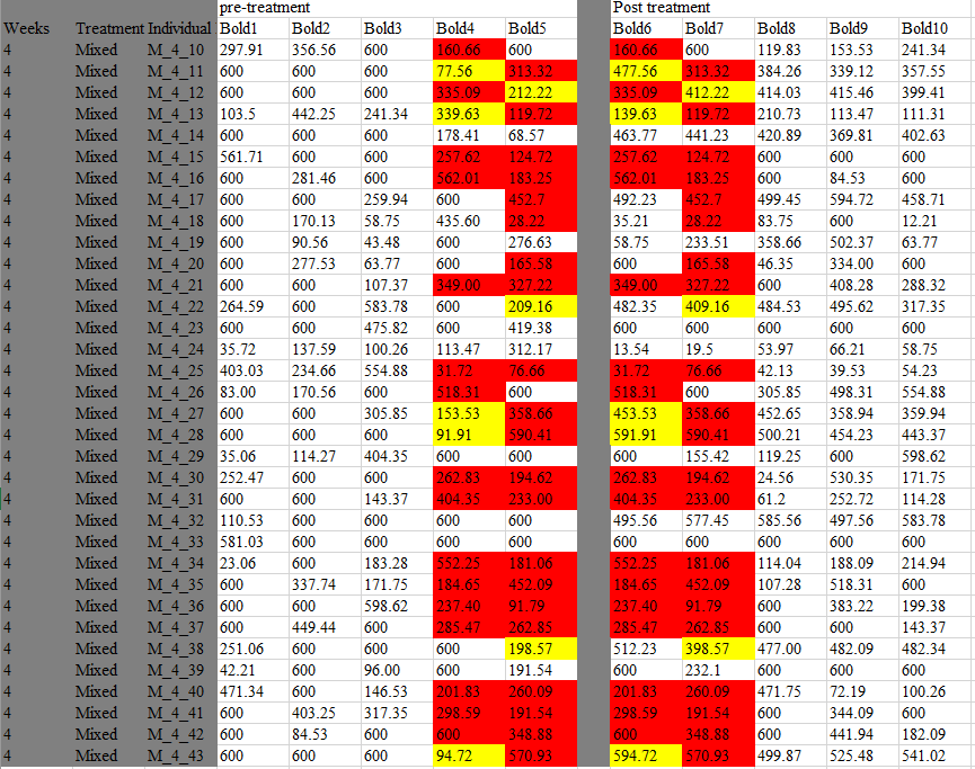
In another blogpost on the topic, Dan Bolnick, editor of American Naturalist and professor at University of Connecticut, explains that the journals actually very much can be expected to take responsibility and to perform data integrity investigations, which his journal did. Bolnick even used to curate a publicly viewable (but not editable) Google Docs file to track the reliability of Pruitt co-authored papers. Some papers actually proved to contain no evidence of irregularities. The list was removed now, after Pruitt lawyered-up. Bolnick’s commendable behaviour stands in stark contrast to certain other editors who now hide behind Pruitt’s lawyer’s letter and the McMaster investigation.
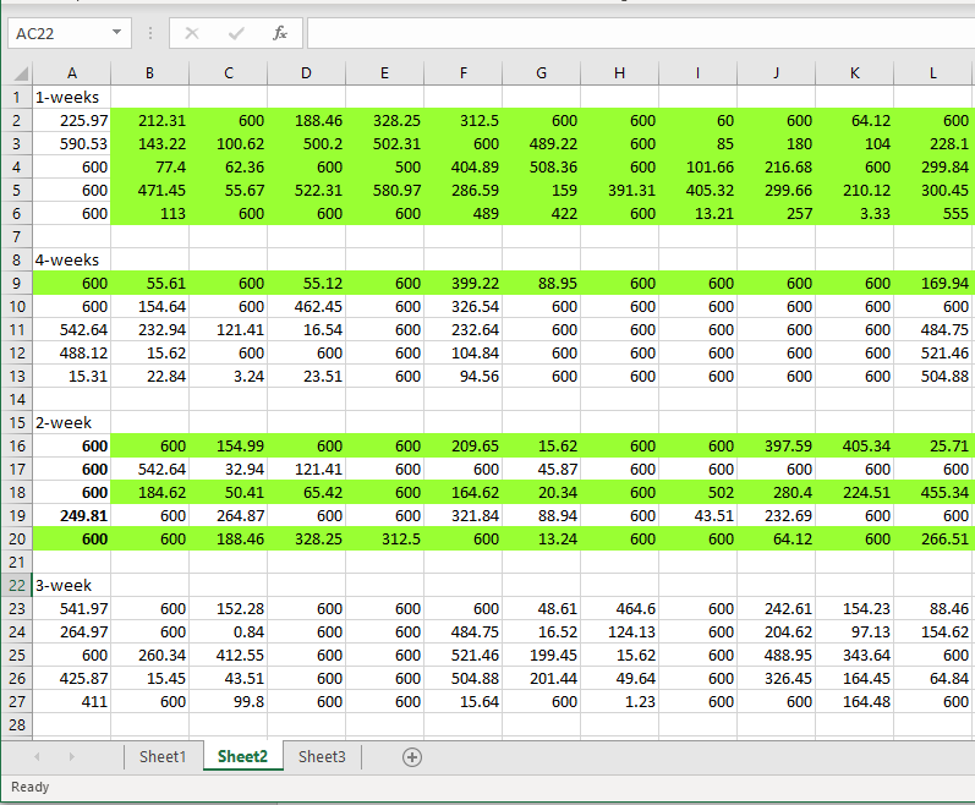
Unlike his lawyer claims, Pruitt even agreed to the first retraction, which happened in American Naturalist. Laskowski quotes him with: “it is well that the paper is being retracted”. But eventually Pruitt changed his mind. Things got out of his control namely. After that retraction, other Pruitt coauthors reached out to Laskowski, the search for data manipulations became a communal effort. Many went on to publish their concerns on PubPeer, where other Pruitt’s coauthors first defended Pruitt, until some switched sides and joined the investigative group effort, like the associate professor Noa Pinter-Wollman at UC Los Angeles. Did these scientists also discover their own beautiful theories, once verified by Pruitt’s data, now in lying in tatters? Possibly.
One former Pruitt collaborator explained why his co-authors initially defended the accused:
“It’s worth remember that lots of us considered ourselves to be good to very close friends with him. You just don’t want to believe something like this.“
And then they looked into their own papers with Pruitt. A co-author shared this about the raw data behind a publication:
“literally 1/2 the data were sequence repeats 10-14 units long but sometimes with select manipulation“
That source also described the communal #PruittData investigation:
“There are 28 channels, on the slack channel where people are looking at this, each of which is dedicated to a paper. […] The sequence repeat pops up a ton. Formulas are pretty common. One person found that a formula was used but it was like + 20.3 or something to better hide the pattern.“

Pruitt’s manipulative approach over his former friends does not work anymore. If anything, people are afraid of his revenge now, rightly or not, time will show. As a source wrote to me:
“Jonathan has a typical response when confronted. He restates the issue, gives excuses that don’t directly address the question, often will say we should remove the questionable data and reanalyze, and then finally will agree to retract if the results don’t hold. This was the pattern until lawyers got involved that is.
[…] When I was early in my career I was also just enamored with him and trusted him. So when he comes dangling a dataset that would turn into a high level paper, you gladly take it and write it up. Later it seemed like what would happen is that he’s send off just chunks of datasets to different people so they don’t see the whole thing. Or he would talk to say a postdoc about an idea, the six months later the data would appear in that postdocs inbox…. so they don’t ever see the stuff being collected, but are thrilled to have the data and to get a famous person to work with.”
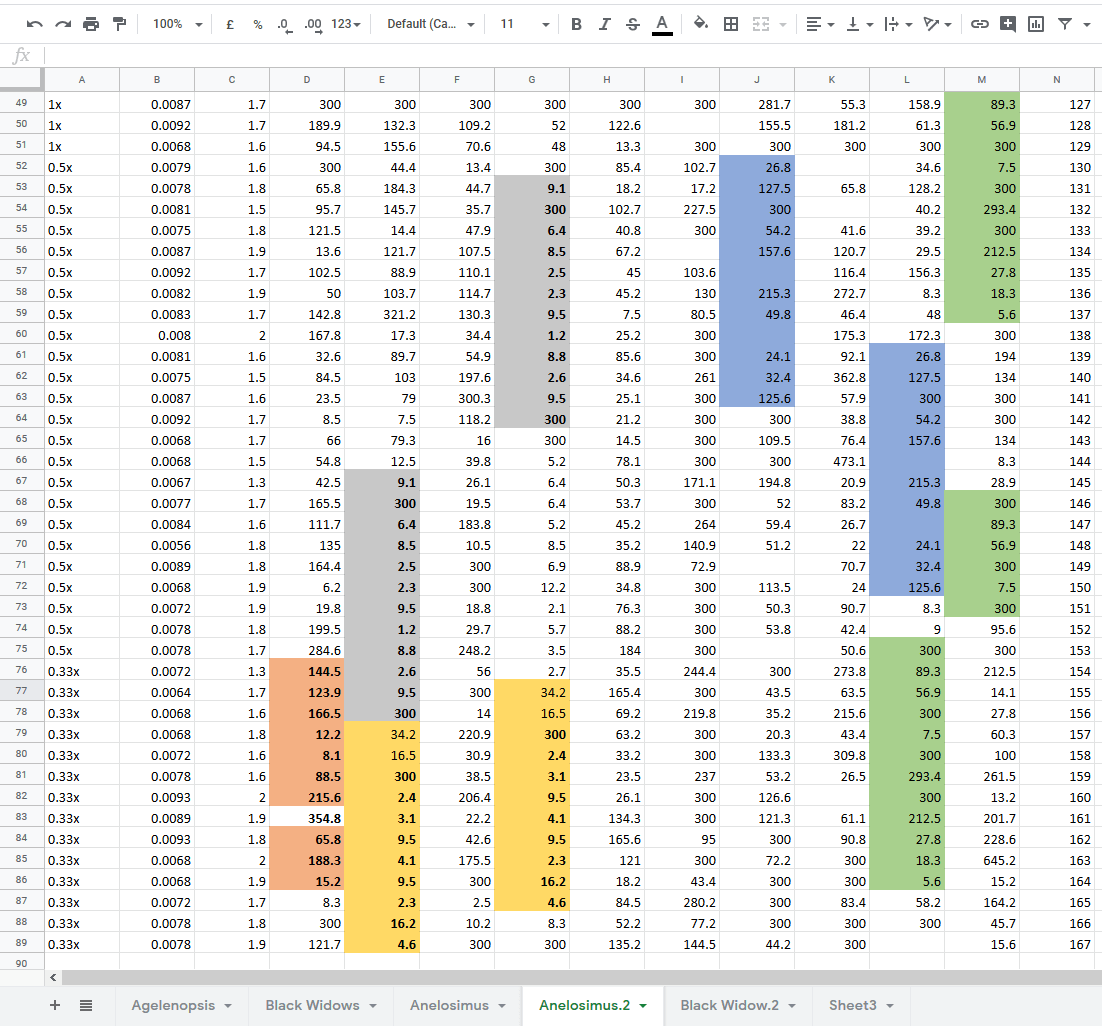
Much of #PruittData problems came out because Pruitt used to share his research data openly. Until he got caught that is:
“Dryad is the data repository for open source stuff. Many journals have started requiring us to upload our data. Jonathan would do that sometimes, but not others. Or he would upload only a portion of the data. This started when one of his own grad students acted as a whistleblower and told another lab about some issues. That lab looked into a bunch of his data on Dryad and found all these issues.“
But now, the lawyer’s letter. Which even Pruitt himself admits is not suitable to scare anyone. He namely wrote to me via Twitter direct message, obviously with reference to the Science article:
“I realize the report made it sound like I legally carpet bombed people; that’s not the case. I know folks have interpreted the action as a flimsy fear-induced gag order. That’s not the case either. I’m happy for folks to engage in public discourse about my data integrity“


PRIVATE & CONFIDENTIAL
WITHOUT PREJUDICE
[….]
Please be advised that our firm has been retained by Jonathan Pruitt with respect to the investigation (if any) being conducted by […] into the paper “[…]” by […] in 20[…]. I understand you have been contacted by Dr […] one of the coauthors, seeking a retraction.
Over the last number of weeks, there has been an online campaign directed at Dr. Pruitt and his work which has come to be known as “#pruittdata” and “#pruittgate”. As part of #pruittgate, a number of academics have organized an extra-institutional online forum for posting, reviewing, and criticizing the data integrity of various of Dr. Pruitt’s research studies and papers. It appears that Dr. […]’s concerns arise from that project.
Dr. Pruitt disagrees that there are any grounds for this paper’s retraction. Any decision about retraction must be conducted fairly and in keeping with professional norms as articulated by the Committee on Publication Ethics (“COPE”) Guidelines on Retractions. It does not appear that this paper meets any of the criteria for retraction as set out in the COPE Guidelines. In particular, the COPE Guidelines do not support retraction if “the main findings of the work are still reliable” or if “an editor has inconclusive evidence to support retraction, or is awaiting additional information such as from an institutional investigation.”
In addition, I am concerned that the procedural fairness of any investigation has been hampered by the manner in which Dr. Pruitt’s work is currently being criticized online. The social media campaign and online forums which spurred this complaint break with the normative practices of the field and very likely prevent a fair assessment of Dr. Pruitt’s work.
The controversy over this particular paper highlights the problems with using an unmediated online forum to attack the data integrity of a body of work. In this case, it appears that the wrong electronic file was uploaded to the forum. The final published paper does not rely on the impugned data.
If […] there is sufficient grounds to retract this paper, it must first notify Dr. Pruitt and provide him with a chance to respond. A premature retraction without Dr. Pruitt’s agreement is likely to further harm his reputation and negatively impact his career in an irreversible manner.
Please confirm that […] does not intend to take further steps at this time
with respect to the above noted paper. Otherwise, if the journal intends to take any further steps, please provide me with correspondence (1) detailing the journal’s concerns, including what evidence it has showing that the paper’s findings are no longer reliable, and (2) outlining the process the journal intends to follow prior to retraction, including when and how Dr. Pruitt will be permitted to respond to any allegations against him.
I am happy to discuss this matter further if you have any questions or concerns. If you would like to speak to me, please arrange a time through my assistant Lori Leblond (lori@millardco.ca, 1-416-920-3123).
Yours truly,Marcus McCann
Update 19.05.2020. Seems Pruitt’s lawyer was successful. The Pruitt et al Proc Roy Soc B: Biol Sci 2016 paper, previously retracted on 26 February 2020, was stealthily de-retracted by the publisher The Royal Society in March. Instead, an Expression of Concern was published on 29. April 2020, announcing “An investigation into these aspects is under way“. This is the deleted retraction:


Donate!
If you are interested to support my work, you can leave here a small tip of $5. Or several of small tips, just increase the amount as you like (2x=€10; 5x=€25). Your generous patronage of my journalism will be most appreciated!
€5.00


Somebody should inform spiderboy’s lawyers:
LikeLike
Pingback: Here’s the letter Jonathan Pruitt’s lawyers have been sending to journals and his former collaborators #pruittgate #pruittdata | Dynamic Ecology
Though Laskowski is completely innocent, it is not unreasonable to speculate that she got a faculty job from his questionable data, from which she got three published papers from, and she may have pivoted off that for more work. This gave her an advantage over other candidates that did not have her great publication record. I dont, however, seeing her rescind her faculty position! Why didn’t she collect her own data? Most of my ideas are wrong from the data that I collect myself, and I kind of wish the same thing happened to her to equal the playing field. But then again, maybe if this had happened, a full fledged cheater who fudged data could have then gotten the position.
LikeLike
Pruitt’s co-author Nicholas DiRienzo now commented on PubPeer
Pruitt et al Behavioral Ecology and Sociobiology (2011)
https://pubpeer.com/publications/2BE2F156C5AC7C0C33939A612FDD9C#1
https://drive.google.com/uc?id=1grJs92VKblsNro0rKGRKNRETuRakZUz7
Pruitt explained it as
DiRienzo concludes
LikeLike
Another comment by same co-author on DiRienzo et al Animal Behaviour (2013):
https://pubpeer.com/publications/FD7055F5D73D09E13C750C435B6695
DiRienzo also found a “lingering formula” and other issues in that paper’s dataset.
He concludes:
LikeLike
Another comment by same co-author on DiRenzio et al Animal Behaviour 2012:
https://pubpeer.com/publications/00E431B139DAF33455AC1FC2418F0F#1
LikeLike
Another comment by same co-author on Lichtenstein et al Behavioral Ecology and Sociobiology (2016)
https://pubpeer.com/publications/1084FEB633DD7021D4D5A954AACFBA#1
“I discovered more repeated sequences, although this time they were almost all identical in sequences although not in horizontal alignment. These duplications are colored and bolded.”
https://drive.google.com/uc?id=1vUuA4FWoOWZfA9JAVZgwUW2YdegcXjN_
LikeLike
Looks like Pruitt’s lawyer letter may have had a chilling effect after all:
https://pubpeer.com/publications/F62202DB4DB0804CD2E65C25764549#8
It seems reasonable to draw a connection between the lawyer letter and the apparent posting and removal of a retraction notice.
LikeLike
The Pubpeer entry reveals that the retraction notice of https://royalsocietypublishing.org/doi/full/10.1098/rspb.2015.2888 was published on 26 February 2020. This
retraction notice has a DOI https://www.doi.org/10.1098/rspb.2020.0255 / doi: 10.1098/rspb.2020.0255
Does this acting by publisher Royal Society imply that the Royal Society is trying to argue that this publication does not exist anymore?
So what’s the added value of a DOI when the DOI of this publication does not dissolve anymore?
LikeLike
Pingback: Interview with JBC research integrity manager Kaoru Sakabe – For Better Science
Pingback: Mr ACE2 Josef Penninger, Greatest Scientist of Our Time – For Better Science
Copy/pasted from https://www.sciencedirect.com/science/article/pii/S0003347213002492 :
“RETRACTED: Linking levels of personality: personalities of the ‘average’ and ‘most extreme’ group members predict colony-level personality, Jonathan N.Pruitt, Lena Grinsted, Virginia Settepani
This article has been retracted at the request of the authors LG and VS. It has come to the authors’ attention that the data on spider boldness reported in this paper appear to contain irregularities in the form of an excess of duplicated values. These duplicated values even span across time points. For example, the boldness value 63.21 sec occurs in both boldness 1, 2 and 3 which were assayed at different times. Furthermore, extensive overlap has been found between this data and that from a different article published the same year: 74.3% of the boldness values are identical to those found in the other publication even though different spiders were assayed. On this basis, the authors LG and VS have lost faith in the reliability of the data and they wish to retract the paper. Author JNP does not agree to the retraction.”
LikeLike
Copy/pasted from https://royalsocietypublishing.org/doi/10.1098/rspb.2020.0255 :
“Retraction: The Achilles’ heel hypothesis: misinformed keystone individuals impair collective learning and reduce group success
N. Pinter-Wollman , C. M. Wright , C. N. Keiser , A. DeMarco and M. M. Grobis
Published:29 July 2020
The authors of the paper by Pruitt J.N., Wright C.M., Keiser C.N., DeMarco A., Grobis M.M., & Pinter-Wollman N. `The Achilles’ heel hypothesis: misinformed keystone individuals impair collective learning and reduce group success’ published in 2016 in Proceedings of the Royal Society B283: 20152888 were recently made aware of problems in the raw data collected by Pruitt J.N. In particular, 86% of the values of the rewarding stimulus in time 9 are separated by an integer (11) from the values in time 11 of the rewarding stimulus. Similarly, 82% of the values in time 10 of the rewarding stimulus are separated by an integer (3) from values in time 12 of the rewarding stimulus. In addition, 21% of the values in time 2 of the rewarding treatment are separated by a fixed integer (8) from values in time 1 of the dangerous treatment.
Furthermore, in the data on individual learning, 80% of the values from time step 5 in the rewarding trial are separated by exactly 10 from the third time point in the unrewarding trials. Similarly, 80% of the values from time step 6 in the rewarding trial are separated by exactly 11 from the second time point in the unrewarding trials. These irregularities are focused on the keystone and generic individuals and no such irregularities are found in the control individuals.
Reanalysis, with these irregularities removed, no longer provides clear support for some of the main conclusions of the study. The authors therefore wish to retract the paper.”
Note that Jonathan Pruitt is not listed as author of this retraction note and note that this information is not listed in this retraction note. This retraction note also does not provide details about the whereabouts of the raw data which were removed because of “irregularities” / “problems”.
LikeLike
And another Retraction (published in July 2020). Copy/pasted from https://www.sciencedirect.com/science/article/pii/S0003347220301342 :
“Retraction notice to “Individual differences in personality and behavioural plasticity facilitate division of labour in social spider colonies” [Animal Behaviour 97 (2014) 177–183]
This article has been retracted at the request of the Editors and authors. After scrutinizing the raw data associated with this paper, the first and second authors discovered irregularities in the form of duplicated data sequences. In particular, identical behavioural profiles were repeated across individual spiders belonging to colonies that were purported to be independent. As these anomalies cannot now be explained, these authors consider the results to be unreliable. They have, therefore, retracted the paper. The data were collected by the third author, who agrees to the retraction.”
Once again “irregularities” and “anomalies” in data which were collected by Jonathan Pruitt and which could not be explained (by Jonathan Pruitt?).
LikeLike
And an Expression of Concern of another paper in Animal Behaviour. Copy/pasted from https://www.sciencedirect.com/science/article/abs/pii/S0003347220301706 (published in August 2020):
“Several concerns have been raised about the study’s integrity and data validity. This expression of concern is to inform readers about the potential issues related to this article. An investigation has revealed that the boldness measures, although not used in this study, contain some anomalous patterns of decimals in recorded latencies. These measures were supposed to be taken with a stopwatch, and thus one would expect the decimals that were recorded to the hundredth to be effectively pseudo-random. Yet, the centi decimals present are commonly repeated. Simulations show that these patterns of repeats should virtually never occur naturally, which raises questions regarding their validity and accuracy. Although this suspect measure is not used in the paper, it was collected as part of the aggression trials, of which other measures were used. Dr. Pruitt has not provided a sufficient explanation for this issue. Given this, Drs. DiRienzo and Hedrick would like to make the readers aware of these unexplained data anomalies. For a full description of the history of the datasets and the investigation done by Dr. DiRienzo, please see this post on PubPeer:https://pubpeer.com/publications/00E431B139DAF33455AC1FC2418F0F ”
First author Nicholas DiRienzo wrote on 23 March 2020 at this Pubpeer thread:
“I agree that the small dataset that is mainly integers makes it hard to detect anomalies (which is why I focused on the boldness data). I do find the three mass/boldness increases curious. I hadn’t found those, but I was trying to avoid sorting the data every to reduce the chances of finding false positives.
It’s hard for me to give this portion of the dataset an endorsement beyond “I think they’re trustworthy.” Another way I could put it is “I couldn’t find any giant red flags, but I’m skeptical.” I made these posts as science demands trustworthy data, and thus even just even having to ‘think’ if they’re trustworthy should give readers pause.”
First author Nicholas DiRienzo wrote on 5 August 2020 at https://twitter.com/Niku_DiRienzo/status/1290997804706328576 :
“1 of 5 resolved. Not a retraction, but did get a Expression of Concern published highlighting the data anomalies. Please read the description below and check out the PubPeer post for more details.”
“I think Animal Behaviour has been incredibly bold. There’s been a lot happening behind the scenes and they’ve powered through everything to do what’s best in each situation. Now, other journals… well, some have had their own best interests in mind.”
“The other issue is that some are treating each paper as an isolated incident as they’re afraid of getting sued even though they should consider the whole of the situation.”
“Some are also only concerned about the influence of the anomalies on the results. If they don’t hold with the anomalies removed then they retract, otherwise they just allow (force) a correction. This is why we’re seeing corrected papers with half the data removed.”
LikeLike
Copy pasted from “Bolnick, A. Sih, N. DiRienzo & N. Pinter-Wollman, 2020. Authorship removal correction for ‘Behavioural hypervolumes of spider communities predict community performance and disbandment’,
https://doi.org/10.1098/rspb.2020.1852 (published: 19 August 2020)”:
“The authors of this correction re-examined data generated by co-author J. N. Pruitt that contributed to the conclusions of the 2016 publication cited above, in a file not originally published with the paper. The file included waiting times (in seconds, ranging from 0 to 600) for individual spiders to initiate a behaviour. We found that certain integers (34, 45, 56, 67, 78 and 89) were substantially over-represented relative to adjacent integers, beyond what would be expected from reasonable statistical distributions. In the light of this over-representation, D. I. Bolnick, A. Sih, N. DiRienzo and N. Pinter-Wollman remove their authorship from this paper.”
Copy/pasted from https://twitter.com/Niku_DiRienzo/status/1296070468491853824 (19 August 2020):
“[1/3] 3rd #Pruittdata paper dealt with. In this case editors would not let us retract and instead wanted the corrections suggested by Dr. Pruitt. This includes rounding the values to the nearest increment of five and reanalyzing https://doi.org/10.1098/rspb.2016.1409
[2/3] There were several other issues not described in the letter that killed my personal confidence in the data. Ultimately, given no good explanation was ever given for how the anomalies occurred, myself and coauthors were unwilling to reanalyze and submit a correction.
[3/3] The only option was to remove ourselves from the paper (and even this proved difficult). As we’re no longer authors. Jonathan Pruitt will be allowed to reanalyze the data and submit a correction on his own.
Deborah Leigh: will it go through another round of reviews though? And will the issues you have with the paper be disclosed to the reviewers? I think that is important! Sorry you couldn’t retract
Nick DiRienzo: They’ve repeatedly told us to keep things confidential which only protects them and Pruitt, not the rest of us. I told them this paper would never pass peer review if these issues were known about at the start, so it should be retracted. That should be the standard but isn’t.
Nick DiRienzo: [1/2] Also, I don’t want to pretend to be innocent. I should have been more concerned about the lack of some information (e.g. trial dates, trial order, etc.). I made assumptions without verifying and did my repeatability calculations off those.
Nick DiRienzo: [2/2] Pruitt doesn’t have those data and doesn’t remember if they were ordered or unordered. The journal doesn’t seem concerned. This means we can’t account for order effects. They might not be there, but we won’t know.
Nick DiRienzo: Here’s their report which they considered final. This is their summary after lots of back and forth. They only care if the anomalies influence the biological conclusions, not anything about how they came to be. https://drive.google.com/file/d/1oM5d0MHEzuAo39CdoJQvWqlaYnMPMYeQ/view
Nick DiRienzo: (…) they’ve repeatedly asserted things are confidential (they’re not, btw). I don’t have a lot of hope for transparency moving forward.”
So how to refer at the moment to https://doi.org/10.1098/rspb.2016.1409 ?
Pruitt (2016, see also Bolnick et al. 2020)?
LikeLike
Copy/pasted from https://twitter.com/DanielBolnick/status/1296294691617615877 (20 August 2020):
“Today some co-authors and I published a “correction” removing our names as authors on a paper https://doi.org/10.1098/rspb.2020.1852 This unusual move deserves explanation despite continuing moves by a coauthor’s lawyers that have had a chilling effect my expression of my scientific views
So, I will limit myself to a few statements of fact: One of the datasets used to establish repeatability of behaviors (not originally posted on dryad) contained data on latency times for spiders to initiate a behavior (0 to 600 seconds)…
As you might expect with latency times, the integer values were exponentially distributed. Except, a handful of integers were vastly over-represented relative to (1) exponential distribution expectations and (2) adjacent integers.
I first noticed that the number 67 was >3x more common than 66 or 68. Odd, but not a clear signal of a problem. On looking for the other over-repesented integers, there was a pattern: each was a 2-digit number with adjacent values on a keyboad: 34, 45, 56, 67, 78, 89, 90.
Each of these is ~3x more common than the flanking integers (e.g., 34 is more common than 33 or 35). I see no plausible biological cause for this pattern, and the probability of this pattern from exponential or other distributions is very low.
The co-author who generated these data offered an explanation for this pattern, invoking unconscious observer bias of a few seconds here and there, and offered to redo the analyses rounding all values to the nearest 5 (e.g., 34 –> 35, etc) & provide a correction.
The journal requested such a correction. To my limited knowledge the editorial board has not ruled out a retraction if the submitted correction proves to be insufficient.
I would ask that the community not trash the ProcB editorial board: this is not yet the final word on this paper, and I expect they are under intense legal pressure to move slowly and cautiously.
As co-authors, we also were very cautious in coming to our decision to remove ourselves. We did this based on lengthy (weeks-long) collective examination of the dataset specifically for this paper, and was not reached lightly or gladly.
We make no claims about how the data came to be flawed, but the origins of the data is secondary to the clear biological implausibility of the numbers (which we documented with extensive statistical analysis), which suffices to lead us to end our authorship with this paper.
I post this thread, speaking as a co-author, because I believe:
1. the scientific record needs to be amended when flaws are found,
2. these changes need to be disseminated to the paper’s audience,
3. that social media is an effective tool for disseminating scientific changes.”
LikeLike
Copy/pasted from:
Pinter-Wollman N. 2020. Authorship removal correction for ‘The legacy effects of keystone individuals on collective behaviour scale to how long they remain within a group’. Proceedings of the Royal Society B 287: 201842. http://dx.doi.org/10.1098/rspb.2020.1842 (published online 19 August 2020).
“Due to recently discovered anomalies in the data collected and curated by J. N. Pruitt for the paper by J. N. Pruitt and N. Pinter-Wollman, ‘The legacy effects of keystone individuals on collective behaviour scale to how long they remain within a group’ published in 2015 in the Proceedings of the Royal Society B282, 20151766, which include formulas in the raw data file, duplication of portions of the data and an excessively high number of repeated values beyond what would be expected in an unbiased sample, N. Pinter-Wollman removes her authorship from this paper.”
So how to refer at the moment to http://dx.doi.org/10.1098/rspb.2015.1766 ?
Pruitt (2015, updated, see Pinter-Wollman 2020)?
Pruitt (2020, see also Pinter-Wollman 2020)?
LikeLike
There are several ways how standardized observations on the social behaviour of spiders, in the field and/or in a lab, can be recorded.
(1): write them by yourself in a note book / field diary / on a standardized form etc. This can be done when you are alone;
(2): use an audio-recorder (various possibilities, including video, wildlife camera, etc.) to record your own spoken observations. This can be done when you are alone;
(3): collect the data together with one or more others who write down your spoken observations in a note book / field diary / on a stadardized form etc.;
(4): use a (modified / simplified) keybord (which it attached to a computer) to enter by yourself the (standardized) observations;
(5): collect the data together with one or more others who use such a (modified / simplified) keybord to enter your spoken observations.
etc.
This list is incomplete. All methods produce raw research data, also called primary research data. I have huge piles of them (note books / field diaries / standardized forms). I only need a scanner / digital camera / mobile phone to make digital copies of these pieces of paper and send these copies to anyone who would like to have a copy (or post them online).
A committee of Harvard University who investigated the serious allegations of research misconduct by Marc Hauser had for example access to a large amount of video/audio tapes taken during observations of monkeys, see for details e.g. https://www.harvardmagazine.com/2012/09/hauser-research-misconduct-reported
I was wondering if any of the co-authors of the Pruitt papers which are at the moment under discussion has even seen (parts of) such kind of raw research data. Am I right that all these co-authors have until now only seen Excel-files etc. with a summary of these raw research data / primary research data?
LikeLike
As far as I can tell the Pruitt collaborators had a hypothesis, told Pruitt, and Pruitt collected all of the data for them to test the hypothesis, and e-mailed in a spreadsheet. Gee, I wish someone else would collect the data I needed for a paper and then all I would need to do is write it up and get it published, and really build up my CV real easy! No wonder Pruitt had so much influence, he made up data that others were to irresponsible to collect on their own, who could use the data to nicely pad up the CV’s for promotion. Nice scam going here…..
LikeLike
Copy/pasted from https://academic.oup.com/beheco/advance-article-abstract/doi/10.1093/beheco/araa073/5898590
“Expression of Concern: Spider aggressiveness determines the bidirectional consequences of host–inquiline interactions, Behavioral Ecology, Published: 28 August 2020
At the request of the Editor-in-Chief, the authors of the paper “Spider aggressiveness determines the bidirectional consequences of host–inquiline interactions,” by Keiser and Pruitt published in Behavioral Ecology in 2014 ( doi.org/10.1093/beheco/art096 ) recently investigated the raw data associated with this manuscript using visual inspection and the R package SequenceSniffer ( https://github.com/alrutten/sequenceSniffer ). Two irregularities were discovered: The presence of these anomalies renders this subset of behavioral data unreliable. The conclusions drawn in the original article are robust to reanalysis after excluding these data anomalies from the file available at Figshare ( https://figshare.com/articles/Data_for_Keiser_and_Pruitt_2014_-_Behavioral_Ecology/11778552 ). Nevertheless, because of the presence of these anomalies, readers are alerted to our concern over the integrity of the remaining data. We will publish a more complete correction once the remaining data have been verified.”
Copy/pasted from https://twitter.com/HiDrNic/status/1299395150968311808 (co-author Nick Keiser):
“Damn, this is not the reason I wanted to get back on twitter, but things need to be said. Our newest Expression of Concern is out in Behavioral Ecology, detailing problems we found with Keiser and Pruitt 2014 BehavEcol. [thread]
A teaching tool in the lab where I did my PhD was that our advisor gave us a previously-collected dataset for our first research rotation which we use to learn statistics and scientific writing. I actually think this is an awesome practice (I’ve done it with 2 of my students).
These data were collected by my advisor in 2010 in Tennessee and given to me, their first graduate student, to analyze and write up in Fall 2012. I loved this paper. It taught me how important individual differences in behavior could be for community ecology.
This paper taught me what “inquilines” were (a type of social parasite) and I fell in love with social spiders and the diverse ecological communities they host in their colonies. This study became part of the foundation for how I viewed species interactions.
This spring, we investigated the data with tools like SequenceSniffer (something I would have never known about eight years ago as a first-year PhD student). The errors we discovered are outlined in the EoC linked above. I was devastated.
This EoC is the product of months of work, and countless reanalyses and emails back and forth. If you’re wondering how these types of discoveries result in Expressions of Concern vs. Retractions vs. Corrections, I don’t think I am at liberty to discuss. I wish we could.
I’ll end with the final sentence of the EoC: “Nevertheless, because of the presence of these anomalies, readers are alerted to our concern over the integrity of the remaining data. We will publish a more complete correction once the remaining data have been verified.””
Copy/pasted from https://twitter.com/dornhaus/status/1299411607362121728 (Anna Dornhaus):
“The answer, if anyone wants to know, is lawyers.” (28 August 2020).
LikeLike
Copy/pasted from https://twitter.com/EvoSarah/status/1329215444272750592 (19 November 2020):
“Unfortunately, I have to join the list of authors retracting a paper on spider behavior. My cosigning authors and I discovered some anomalies, which were confirmed through an investigation by @ASNAmNat https://journals.uchicago.edu/doi/10.1086/712483 ”
Copy/pasted from https://www.journals.uchicago.edu/doi/10.1086/712483
“Retraction
James L. L. Lichtenstein, Ambika Kamath, Sarah Bengston, and Leticia Avilés
The article “Female-Biased Sex Ratios Increase Colony Survival and Reproductive Output in the Spider Anelosimus studiosus,” published in the November 2018 issue (pp. 552–563), is retracted by request of The American Naturalist and the authors of this retraction statement. Investigation by the journal, which was fully examined by all authors, revealed a 43-row repeated sequence in the sex ratio estimation data and nearly identical data distributions in colony size across collection sites. These anomalies in data collected by Jonathan N. Pruitt could not be explained, undermining the credibility of the article’s results. On this basis, the authors of this statement regretfully retract this article.
Electronically published November 18, 2020”
Jonathan Pruitt is not mentioned in this list of authors of this retraction note. Does this imply that Jonathan Pruitt does not agree with this retraction?
LikeLike
Copy/pasted from https://royalsocietypublishing.org/doi/10.1098/rsbl.2020.0588
“Retraction:
Behaviour, morphology and microhabitat use: what drives individual niche variation?
Raul Costa-Pereira and Jonathan Pruitt
Published:26 August 2020 https://doi.org/10.1098/rsbl.2020.0588
See original article (Biol. Lett.15, 20190266. (Published online 5 June 2019) (doi:10.1098/rsbl.2019.0266 )
Following publication of the article by Costa-Pereira & Pruitt, the journal was made aware of potential problems with the associated raw data collected by Pruitt J. An investigation into the data detected duplicated values and as such, results drawn from these data cannot be considered reliable and the journal has decided to retract the article accordingly.
Biology Letters / © 2020 The Royal Society / Published by the Royal Society. All rights reserved.”
LikeLike
Copy/pasted from https://www.journals.uchicago.edu/doi/10.1086/713144 : “The article “Iterative Evolution of Increased Behavioral Variation Characterizes the Transition to Sociality in Spiders and Proves Advantageous,” published in the October 2012 issue of The American Naturalist (pp. 496–510), is retracted by The American Naturalist and the authors of this retraction. Investigation by the journal, which was fully examined by all authors, revealed duplicate ratios of spider mass to prey mass, which was often an exact value (e.g., 0.3, followed by 0.33 and 0.34 exactly). Similar anomalies, with redundant predator-prey mass ratios, were also found for other size categories. These anomalies in data collection by Jonathan N. Pruitt could not be explained, undermining the credibility of the article’s results. On this basis, the authors of this statement regretfully retract the article. (…). Published online January 19, 2021”.
Christopher Oufiero, Leticia Avilés and Susan Riechert are listed as authors of this retraction note.
LikeLike
Copy/pasted from a thread at https://twitter.com/Niku_DiRienzo/status/1357369889489494017 (posted on 4 February 2021):
“Figure I’ll give a one year #pruittdata #pruittgate update on two papers in BES: Lichtenstein et al 2016 and Pruitt et al 2011. Myself and coauthors requested retractions for them on 1/27/20 and 2/3/20 respectively after finding major data anomalies in both. I documented those issues here: https://pubpeer.com/publications/1084FEB633DD7021D4D5A954AACFBA , and here: https://pubpeer.com/publications/2BE2F156C5AC7C0C33939A612FDD9C
The BES editorial board was initially highly concerned and recognized the issues. After extensive back and forth between myself/coauthors and Jonathan Pruitt about the anomalies in Pruitt-collected data, the board agreed to retract the papers on 09/04/2020. Since then I have written monthly check-in emails asking the status of the retraction statement. The typical response has been that this process is largely out of their hands. On 01/13/2021 the retraction text was sent to coauthors for approval, asking for a response by 01/20/21.
Note that this text was only for Lichtenstein et al 2016, and not Pruitt et al 2011. When I asked about the 2011 retraction text I again received a response that it’s out of their hands at this point. Again, Pruitt et al 2011 had a formula in it to generate a new observation. Additional issues were single-cell differences between the two versions. Pruitt’s responses varied from the formula being used in a ‘sensitivity analysis’, to it being a different measure and not being used in the analysis despite stats/versions indicating otherwise. So even with these major issues which indicate clear manipulation the papers are still not retracted. Personally, I don’t think this is the fault of BES (they’ve been very tolerant of my pestering), but rather processes, foot dragging, and maybe legal actions at higher levels.
Still, as someone who is out of the behavior field and leaving academia shortly, this whole process seems broken. I’m still shocked that ProcB allowed for us to retract our names and allow a shoddy reanalysis of clearly problematic data vs. just retracting the paper…
I’m shocked that I have my name on two papers here that have obvious data issues with no valid excuse given in a year, yet they’re still out there. I get these things take time, but at some point the actual issue and solution is just being avoided.”
Niels Dingemans responded on the same day: “On a positive note, journals not making a stand expose themselves as failing to protect the values we hold dear as a scientific community. That’s not bad: it helps us identify them, pushing us to refocus our editorial/reviewer time towards those that do protect our interests..”
Source: https://twitter.com/DingemanseLab/status/1357410083064455174
See https://www.springer.com/journal/265 for backgrounds about the journal in question. Lots of Associate Editors are affiliated to this journal, see https://www.springer.com/journal/265/editors How comes that these Associate Editors are unable to solve this issue?
LikeLike
Another update about Jonathan Pruitt at https://twitter.com/GrinstedLena/status/1357791220425195520 (posted on 5 February 2021): “Never thought I’d be so happy to get a paper retracted! But it’s been a horrendous fight for nearly a year, and finally I got the (only acceptable) final decision from Proc B today to retract our paper that linked social spider personality with task differentiation. #pruittdata”
See https://pubpeer.com/publications/11ED07D6DCDE43FFC88DFEA189874B
Also an update in a short thread at https://twitter.com/RRoyaute/status/1357730477638094849 (also posted on 5 February 2021):
“An #ExpressionofConcern for my 2015 paper in @ESAEcology https://esajournals.onlinelibrary.wiley.com/doi/10.1002/ecy.3292 We found anomalous patterns of duplicated values in several of the data spreadsheets (issues summarized here: https://github.com/rroyaute/Royaute-Pruitt-Ecology-2015-Data-and-Code/blob/master/SequenceSniffing/Summary ). I know the editorial team @ESAEcology is working very hard to determine what may have caused these duplications and will update on the situation as soon as possible”.
See https://pubpeer.com/publications/C6ACC9E8B7FE9CE4DB3AC705B27468
LikeLike
Copy/pasted from https://link.springer.com/article/10.1007/s00265-021-02997-3 : “Retraction Note to: Behav Ecol Sociobiol (2011) 65:1987–1995 https://doi.org/10.1007/s00265-011-1208-0 . This article (Pruitt et al. 2011) has been retracted by the Editors-in-Chief at the request of the authors. After publication, the authors found anomalies in the raw data that were collected. The conclusions presented based on these data are therefore unreliable. Nicholas DiRienzo, Simona Karlj-Fiser, J. Chadwick Johnson, and Andrew Sih agree with this retraction. Jonathan Pruitt has not explicitly stated whether he agrees with this retraction. Published: 11 March 2021.”
See for backgrounds https://pubpeer.com/publications/2BE2F156C5AC7C0C33939A612FDD9C and a recent thread at https://twitter.com/Niku_DiRienzo/status/1370007020976308227
LikeLike
Copy/pasted from https://dynamicecology.wordpress.com/2021/03/12/friday-links-284/ :
(….) “The latest #pruittdata retraction just dropped. It’s Lichtenstein et al. 2016 Behav Ecol Sociobiol. It’s for anomalous strings of repeated sequences of observations, and formulaically generated observations, that Jonathan Pruitt couldn’t explain. Pruitt didn’t agree to the retraction, because of course he didn’t. Lead author James Lichtenstein and co-author Nick DiRienzo each spent something like 150-200 hours investigating the data, writing reports on it, and evaluating Pruitt’s purported explanations for the anomalies. Here’s Nick DiRienzo’s detailed PubPeer writeup of the anomalies https://pubpeer.com/publications/1084FEB633DD7021D4D5A954AACFBA Kudos to all the co-authors for doing the right thing; it sucks that you had to do it.
“And the hits just keep on coming.” https://www.youtube.com/watch?v=WQZqJ_-WAO8 You said it, Tom. Grinsted et al. 2013 Proc B also was retracted this week. You should click the link https://royalsocietypublishing.org/doi/full/10.1098/rspb.2021.0335?af=R and read the retraction notice, it’s exceptionally detailed. Kudos to co-authors Lena Grinsted, Virginia Settepani and Trine Bild for bringing the issues with the data to the journal’s attention and requesting the retraction. Pruitt is now up to a dozen retractions. That doesn’t count the various corrections and Expressions of Concern, or any of the many papers still under investigation. Protip: try not to do things that result in your Wikipedia page looking like that last link.
Whoops, make that 13 retractions. It’s hard to keep up… Pruitt et al. 2011 Behav Ecol Sociobiol just bit the dust. Kudos to co-authors Nick DiRienzo, Simona Kralj-Fišer, J. Chadwick Johnson, and Andy Sih for fighting to get this paper retracted as soon as they discovered the data were full of anomalies. Want to know exactly what the anomalies were, how Jonathan Pruitt tried to explain them (totally unconvincingly), and what it’s like to go through a back-and-forth with him? Here’s co-author Nick DiRienzo with the blow-by-blow. Amazingly, Pruitt still has a ways to go before his name shows up here https://retractionwatch.com/the-retraction-watch-leaderboard/ (Note that this paragraph was updated a few hours after posting to include Andy Sih, whom I inadvertently left out originally. My bad.)” (…..)
LikeLike
Copy/pasted from https://www.nature.com/articles/nature13811 (Site-specific group selection drives locally adapted group compositions, Jonathan N. Pruitt & Charles J. Goodnight, Nature volume 514, pages 359–362, 2014):
“26 February 2021. Editor’s Note: Readers are alerted that the reliability of some of the data presented in this Article is currently in question and is being investigated by the editors. A further editorial response will follow when the issues are resolved.”
It seems to me that this “Editor’s Note” has to be interpreted as an Expression of Concern.
See also https://pubpeer.com/publications/77C43A85588D997CA3DE730344AE3B (with a whole bunch of new questions, posted on 17 April 2021 by “Atheropla decaspila”).
LikeLike
Copy/pasted from https://dynamicecology.wordpress.com/2021/04/23/friday-links-289/ :
“(….) The #pruittdata saga started with an Am Nat paper (see here for background). Now, #pruittdata is (hopefully!) over as far as Am Nat is concerned https://twitter.com/DanielBolnick/status/1384100738570194948 . Pruitt et al. 2012 Am Nat https://www.journals.uchicago.edu/doi/10.1086/663680 has received a correction https://www.journals.uchicago.edu/doi/10.1086/714866 and an unusually detailed Expression of Concern https://www.journals.uchicago.edu/doi/10.1086/714867 . Which means that all of Jonathan Pruitt’s Am Nat papers have now been retracted, corrected, and/or subjected to EoCs. As someone who’s been heavily involved with Am Nat’s investigations, boy do I wish I could say the saga is over for everyone else too. But it’s not. Not even close. There are still investigations ongoing at various other journals (see below). The McMaster University investigation is still ongoing (or it was as of a couple of months ago, anyway). Is Tennessee still investigating?
Speaking of ongoing #pruittdata investigations…I think I missed this at the time, but back in late Feb. 2021, Nature attached an Expression of Concern to Pruitt & Goodnight 2014. So, if you’re scoring at home, it took Nature ~13 months to get around to publishing an EoC that merely says (in so many words) ‘concerns have been raised; we’re investigating’. Even though they have in fact been investigating (or at least, have said that they’re investigating) that whole time. That’s Nature for you. Bob Trivers had to fight them for years and self-publish an entire book to get them to retract his own paper https://www.nature.com/news/symmetry-study-deemed-a-fraud-1.12932 .
One more #pruittdata link: I second Flo Débarre’s comments https://twitter.com/flodebarre/status/1384166692280958984 . Investigating #pruittdata for Am Nat was an enormous amount of work, but it needed doing and it needed to be done right–thoroughly, promptly, and fairly. I’m proud to have so many colleagues who care so much about getting it right. I hope we’ve set an example that others will be inspired to follow if–god forbid–they’re ever faced with a similar situation in future. (…)”
Sorbus torminalis, an anonymous Pubpeer commenter, is one of the 8 authors of this EoC. It is towards my opinion highly unusual that efforts of an (anonymous) commenter at Pubpeer results in being a co-author of an EoC (or of a Retraction Note).
LikeLike
Daniël Bolnick stated on 12 May 2021 at Twitter: “Opening the black box: a history of the past 17 months of investigation & retractions of an author, from my personal perspective: https://ecoevoevoeco.blogspot.com/2021/05/17-months.html It is time for some transparency.”
“As an aside – Pruitt has frequently been asked to provide original paper copies of data to validate the information in the digital Dryad repositories, and so far has not done so. I did get confirmation from some former undergraduates in his lab who worked on the affected papers, and who stated “we always collected data in the lab on paper data sheets”. They also challenged his claim that spiders were tested in batches of 40 (which he used to explain duplicated numbers, because all spiders in a batch might respond simultaneously and be given the same time). They stated that “the standard practice was to assay between 5-8 individuals at a time, each with a dedicated stopwatch”.
So where is this information? A highly recommended read. #pruittdata #pruittgate
LikeLike
Copy/pasted from https://doi.org/10.1016/j.anbehav.2021.01.010 :
“Expression of concern: “The personality types of key catalytic individuals shape colonies’ collective behaviour and success” [Animal Behaviour 93 (2014) 87–95].
This is a note of an expression of concern related to the publication titled Pruitt, J. N. & Keiser, C. N. (2014). The personality types of key catalytic individuals shape colonies’ collective behaviour and success. Animal Behaviour, 93, 87–95.
Upon more detailed examination of the data in this manuscript, concerns have been raised regarding repeated sequences of values throughout the collective foraging data. Using both visual inspection and the code SequenceSniffer ( https://github.com/alrutten/sequenceSniffer ), we discovered that 55% of collective attack data represent repeated values, even to the hundredth decimal place. There are 99 non-unique latency values (i.e., they are repeated at least once) out of a total 180 assays. This does not include 600s, as those repeats represent the truncated maximum value of a 10 minute behavioral assay and are expected. 36 of these repeated values represent three sequences of six values that are transposed between multiple rows in a single column and six columns on three different rows. Currently, there is no biological or methodological explanation for these highly unlikely patterns, which casts doubt on the validity of the data. Further consideration will be given once original notebooks are provided for cross-referencing. This expression of concern serves to inform readers about the potential issues related to this article. The original dataset provided to Keiser by Pruitt is available on Figshare: https://doi.org/10.6084/m9.figshare.11786505.v1 .”
Author Carl N. Keiser states in a recent comment at https://pubpeer.com/publications/D05B3D97C9477C4A6E78D64354295C :
“For transparency, I have now uploaded a second excel file onto my figshare page which highlights the duplicated sequences described in this Expression of Concern: https://figshare.com/articles/dataset/Data_for_Pruitt_and_Keiser_2014_-_Animal_Behaviour_xlsx/11786505 . Duplicated sequences are denoted with via highlighting with same color.
For context, this experiment was conducted collaboratively by members of the Pruitt Lab at the University of Pittsburgh in 2014. The boldness assays on individual spiders were conducted by myself and the undergraduates listed in our acknowledgements section. As I recall, the boldness data were recorded into shared lab notebooks and entered into excel sheets on a shared lab computer. We then used a random number generator to place individuals into each experimental colony. As I recall, the collective behavior assays were conducted by Pruitt and myself. These data were recorded in shared lab notebooks and entered into excel spreadsheets on a shared lab computer. I do not have access to any of the original notebooks, as they remained in the Pruitt Lab. The data were analyzed by Pruitt, but one of my tasks was to create the figures, so I was given excel sheets to do so. It wasn’t until 2020 that the repeated sequences were brought to our attention. As noted in the expression of concern: ” Further consideration will be given once original notebooks are provided for cross-referencing.””
LikeLike
Jonathan Pruitt has re-activated his Twitteraccount https://twitter.com/agelenopsis He states that he is a “writer” and that he is at the moment residing in “Rural Florida”. The tweets reveal that he has in the meanwhile written a novel (“I’m currently in the #amquerying stages of working on my fantasy novel, A Sinking Monolith (working title).”, 21 May 2021). Pruitt tweeted on 22 May 2021: “Confession: I wrote most of my current manuscript in a gaming store. What’s a writer confession of yours?”
Does this imply that Jonathan Pruitt is not anymore affiliated to McMaster University and/or that Jonathan Pruitt has a long-term holiday and/or that something else is going on? Any news about the investigation of McMaster University?
LikeLike
hi Leonid,
Do you happen to know that it is correct to state that the PhD degree of Jonathan Pruitt was (recently) revoked? Sources: https://twitter.com/Niku_DiRienzo/status/1458808469813878791 and https://trace.tennessee.edu/utk_graddiss/842/ (“This paper has been withdrawn.”). Do you happen to know if Jonathan Pruitt is still enployed by McMaster University?
LikeLike
I asked the University of Tennessee now.
LikeLike
LikeLike
See https://www.science.org/content/article/embattled-spider-biologist-resigns-university-post for some new developments (published on 12 July 2022).
See also https://www.cbc.ca/news/canada/hamilton/johnathan-pruitt-investigation-mcmaster-resigns-1.6517727 and https://freethoughtblogs.com/pharyngula/2022/07/14/the-pruitt-stink-lingers-on/
LikeLiked by 1 person
Pharyngula has it correct in response to the hand-wringing in the Science post: “Hey, confused journal editors and researchers, it’s easy to tell what work of Pruitt’s remains trustworthy: NONE OF IT.” Untrustworthy people do not produce trustworthy science.
LikeLike
Copy/pasted from https://www.nature.com/articles/d41586-022-02156-2 (published on 10 August 2022):
“Pruitt, now a science teacher at Tampa Catholic High School in Florida, declined to comment for this story.”
LikeLike
Crap, I was hoping for an artistic career, like Irina Stancheva….
LikeLike
And another one. Copy/pasted from https://doi.org/10.1093/beheco/arac081 :
“Retraction to: Spider aggressiveness determines the bidirectional consequences of host–inquiline interactions, Behavioral Ecology, Published: 13 September 2022.
This is a retraction to: Carl N. Keiser, Jonathan N. Pruitt, Spider aggressiveness determines the bidirectional consequences of host–inquiline interactions, Behavioral Ecology, Volume 25, Issue 1, January-February 2014, Pages 142–151.
Following their Expression of Concern, the Editor-in-Chief and first author are retracting this article due to irregularities in the original data collected by the second author. Although the overall conclusions drawn were found to be robust after excluding these anomalies, the second author has been unable to provide the necessary raw data to identify the source of the irregularities or to verify the remaining data.”
Copy/pasted from https://twitter.com/HiDrNic/status/1580238755465555972 : “It’s my first day back from parental leave, and just noticed this was published last month. I wrote the Expression of Concern two years ago. Nice to be done with it, but this one stings. Data given to me in my first semester as a PhD student.”
See also https://pubpeer.com/publications/BF638A197BC80D145674D8118BE37F
LikeLike
His Stancheva maneuver: “Pruitt Pest Control: using the latest research to get spiders to eat your cicadae !”
LikeLike
And another retraction.
Copy/pasted from https://www.nature.com/articles/s41586-023-05882-3 :
“Retraction Note of “Site-specific group selection drives locally adapted group compositions, Nature volume 514, pages 359–362. 2014, published online 1 October 2014, https://doi.org/10.1038/nature13811 “.
The Editors have retracted this article. Concerns were raised regarding potential anomalies in the census and experimental data on the aggressiveness and docility of the spiders and the experimental data on prey availability. Post-publication review concluded that the data are not reliable. The Editors therefore no longer have confidence in the results and conclusions of this article. Jonathan N. Pruitt disagrees with this retraction. Charles J. Goodnight is deceased. Published: 06 March 2023.”
LikeLike
Copy/pasted from https://secretariat.mcmaster.ca/app/uploads/RI-Pruitt-summary-of-findings.pdf : “In brief, the facts submitted and accepted by the Committee confirmed that identical values from the paper, studying one species were transferred to the paper published years later studying a different species. Dr. Pruitt did not provide a factual explanation of how this had happened, and their explanation was not accepted by the Committee. Dr. Pruitt’s “hypothesis” for why and how data from one study would be transferred to the data set of another study and end up being inserted in the manuscript was not accepted by the Committee because the “why” does not make sense and the “how” is not even hypothesized.”
See also https://dailynews.mcmaster.ca/worthmentioning/update-on-research-misconduct-case/ (published 11 May 2023).
LikeLike
Its remarkable to me how LAZY he was of a fraudster (cut and paste whole data from previous studies).. If he had been a little more careful to randomize the digits in the cells of the excel spreadsheet a little more he still would have his job and fame:
https://www.popsci.com/jonathan-pruitt-studies-how-spider-societies-function/
LikeLike